… some further feedback…
Well, I certainly agree that you need to wait at least 3 images until the exposure value has stabilized. However, I noticed with various different sensors a drift requiring much longer waits until the exposure had stabilized. Actually, this temporal behavior was different depending on what the combination of initial exposure vs. the target exposure was during testing.
These experiments were done long ago, but during that experiments I of course made sure every auto function of the image processing pipeline was switched off. Well, the processing pipelines might have changed in the intermediate time, I do not know the current status. Maybe the cameras react today faster than 2-3 years ago with exposure changes.
Let me remark that when you are using exposure fusion, you do not really need to get precise exposure times. As long as the exposures are consistent from frame to frame, you will not notice anything. The exposure fusion algorithm does actually not care what the real exposures are. This is different when you switch to real HDR work - here exact exposure values are normally required (You can estimate the exposure values after the fact, but that is noticeably more complicated). In case you want to upgrade later to a full HDR workflow, exact exposure values make your life easier.
In any case, the delayed and non-reproducable response when switching exposure times was the reason I abandoned this approach in favor for a tunable LED source.
Also, at least in theory, with a tunable LED source, you do not need to wait 3 frames, as there is no change in the camera parameters at all. The wait times in my approach are connected to the fact that I have not yet synchronized camera and LED source (this will have to wait for the next major update of the scanner).
Initial experiments with 8 bit DACs revealed that the dynamic range would be too low for capturing most Super-8 color reversal material, so I swapped the DACs out for 12 bit ones. Even so, the dynamic range is barely enough; especially towards the lower illumination levels, a single step in digital brightness results in a large difference of illumination. The five different exposure levels spaced 1 EV apart are the maximum I can currently realize with my 12 bit DACs and the LEDs chosen. Limits come from the available LED output (not enough power) and the color changes introduced by varying the current through the LEDs (this is a tricky one: basically, it is connected to the operating temperature of the LED in question. And of course, that temperature changes constantly at a rapid pace during scanning…). Lastly, even a 12 bit DAC is not really precise enough to cover a larger dynamic range than about 5 EVs.
Let’s step back a little bit. In fact, a lot of people do not bother to work with multiple exposures of a single frame, just use a single, well-chosen exposure. In this case, in very dark image areas you notice a reduced contrast with increased noise, and very bright image areas of the frame might easily burn out.
The reason for this can be understood with the help of the diagram below. It shows the response curve of a camera sensor - what pixel value (y-axis) it will output when exposed to a certain brightness (x-axis).
This is a typical camera curve - from cheap webcams to high-end DLSRs (not talking about the raw format here!) you will find a response curve very similar to this one.
Now, there are two parts of this curve where the response curve becomes rather flat; I am talking about the flattened parts of the curve in dark areas (-5 EV to -2 EV) as well as in the bright areas (anything above about 1 EV in the diagram). In these these exposure areas, a rather large difference in exposure will result in only a minor change in bit-values of the output image. Add the sensor noise into this equation and you end up in the dark parts of the image with noisy, rather structureless blob. In the brighter parts of the image, the highlights are squished (the contrast is reduced as well) until the brightest level a 8-bit/channel image can record is reached - everything brighter will just be mapped to the pixel value 255.
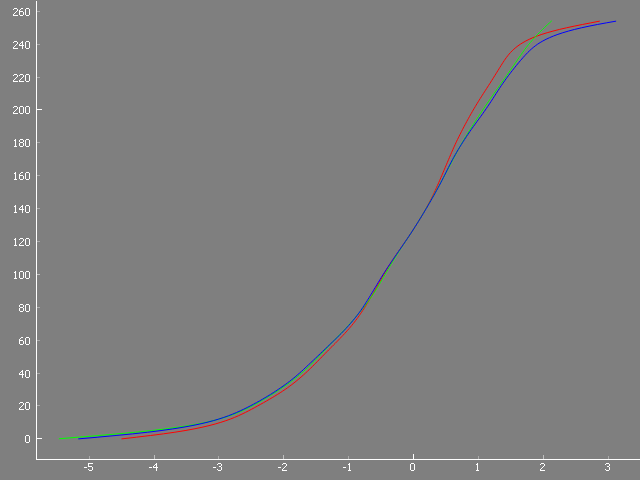
Well, ideally, you want to use only the more or less linear part in the gain curve of your camera, in the case below from -2 EV to about 1 EV for scanning. Your image will more or less mirror the original contrast of your frame, nothing gets squished. That is a working range of about 3-4 EVs.
Now, a difference of 3 EV is not enough for scanning color-reversal film. From experience, I think the range of EVs you are dealing with color-reversal film is between 7-9 EVs, depending on the quality of the film stock and the exposure situation. If you you want to capture such a huge dynamic range, you will need to capture several different exposures from a single frame. (The above gain curve is actually the gain curve of the HQ camera, by the way.)
Assuming for the moment that covering 7 EVs is enough (and for various reasons, that is a quite valid assumption), you would be actually fine to capture just two exposures. I have seen people doing just that. The results are fine, but if you look closely at their results, you notice often some faint banding in the areas where the exposure fusion switched from one exposure to the other one.
So, of course, three exposures are even better. And in fact, I have done quite some scans with only three exposures, utilzing a constant LED source and different exposure times. In this case, I spaced the different exposures larger apart, from 1.5 EVs to 2.5 EVs in order to scan as much of the exposure range as possible.
Now, why do I capture currently with five exposures? Well, there are several reasons. Most importantly, a small patch captured perfectly in one exposure is also captured quite decently in the two neighboring exposures. In a finely tuned exposure fusion algorithm, this leads to a reduction of the camera’s noise level, as more information is available and averaged during the calculation this specific pixel. And with my exposure settings (exposure time = 1/32 sec, digital gain = 1.0, analog gain = 1.2, mode 3) the camera is noisy on the pixel level…
Also, the risk of banding is greatly reduced because for most of the image area, the pixel’s output is an average of at least three exposures.
Finally, I just was not satisfied with the image definition I could achieve in the dark areas of the image - I wanted some headroom here for color grading purposes. Both ends of the density spectrum of the film are recorded only by a single exposure - namely the brightest and the darkest exposure in your exposure stack. While with color-reversal film the highlights are not too challenging, as the original film response curve flattens out here anyway, color-reversal film has a rich image structure in the dark parts of the image.
That is the reason I added additional exposures to get more information from the darker parts of the frame - see below…
Well, that’s simple. My naming of the different exposures simply reflects the purposes of the exposures. Here’s the full list:
- Highlight Scan: the purpose of this scan is actually to reproduce even the brightest image parts of the frame. Because of this, the exposure for this scan is chosen in such a way that the brightest image areas stay in value below the flat shoulder in the above pictured gain curve. Indeed, if you look at the highlight scan posted above, you can use a color picker in the perforation hole to check: the 8 bit values of each color channel should be in the range of 240 to 250. Of course, the brightest highlight in the actual frame cannot be brighter than the light source itself - so any highlight contained in the frame will be captured faithfully, without saturation of the scanner’s sensor, in the highlight scan.
- Prime Scan: this scan is a little brighter (+1 EV) than the highlight scan, so any real highlight in the original frame is burned out in this scan. However, generally this +1EV-scan delivers sufficient image details in most of the image area and that’s why I call it the “Prime Scan”. This scan turns also out to be the most similar to the output result of the exposure fusion algorithm.
- Shadow Scan 00:
- Shadow Scan 01:
- Shadow Scan 02: - all these scans get brighter and brighter in appearance. Their sole purpose is to record as much shadow detail as possible. Since the film emulsion of color-reversal stock goes very deep into the shadows, there is a lot of recoverable detail hidden here. (Note that this is not the case with the burned out highlights - there is no chance of recovering detail lost due to a too bright film exposure. That’s the reason only one highlight scan is present, in contrast to three different shadow scans.)
I hope this makes my naming of the different exposures a little bit more transparent. Some additional information on how I capture frames can be found here and in the posts following this entry. You will note that I never adjust my scanner’s exposure values to the film stock I am scanning - they are referenced to the maximal output the LED light can achieve and stay constant, whatever footage or film stock I am scanning.
Well, no, I am not confused. And yes, I do use mode 3, which indeed has a native resolution of 4056 x 3040 px. Before I explain, let me give you some numbers (this is a Raspberry Pi 4 as server, connected via LAN with a Win10 PC):
- Scan Resolution 4056 x 3040 px, (mode 3): 4 fps in live preview, using a LAN-bandwidth of 200 MB/sec. Scan time (5 exposures) for a single frame: 3.5 sec
- Scan Resolution 2028 x 1520 px (scaled down from 4056x3040px , mode 3): 10 fps in live preview, using a LAN-bandwidth of 155 MB/sec. Scan time (5 exposures) for a single frame: 2.3 sec
So: I am using the HQ camera in mode 3, but let the camera scale down the original image to a lower resolution. That gives me a temporal advantage of about 1.2 sec per scanned frame, reducing overall scan time for a larger film project (40000 frames → more than half a day).
Here’s a comparision between the image quality obtained with the full-scale 4056 x 3040 px resolution of mode 3

and the quality obtained with half that resolution (2028 x 1520 px, mode 3)

For my taste, the drop in image quality is not so noticeable that it warrants the additional +1 sec delay for each frame scan.
Well, I have uploaded the exposure fusion result of two scenes I used above in the original resolution, but as an encoded video file. The original data would just be too large to store it somewhere (I also have a rather slow internet connection). Anyway, this here should be the download link.