I have been working a little bit on visual improvements of Super-8 material; the results start to look promising. Specifically, it seems that one can recover more image detail than originally thought by reducing the film grain of the source material appropriately.
However, in very noisy parts of the footage, there is an effect visible which I am currently calling “pixel dance” - rather large patches of the scence jump slightly to the beat of the film grain.
While this is not noticable in the resolution I want to deliver the files (960x720 px), it is noticable in higher resolutions. Here’s an example:
(top half is the enhanced version, showing “pixel dance” in larger resolutions, bottom half is one of the original scans as reference, showing quite some noise due to film grain in the same areas)
Actually, I know the reason for this: the motion-estimation algorithm (implemented via avisynth software/scripts) locks onto the noise introduced by large patterns of the film grain. I tried to prefilter the input of the motion estimation algorithm to reduce this noise, but the filtering algorithms available in avisynth are limited in this respect.
There are several ways to circumvent this situation. One way would be to improve the current motion estimation - this would probably require to switch from the avisynth base to an own software implemention, a task I currenty do not want to go into. Or, as mentioned above, simply stick to lower resolutions.
Another way would be to add back again more of the original noise to cover up the pixel dance. That is actually what some people are doing (this also covers other errors from the motion estimation algorithm). Yet another approach would be to use non-stabilized footage - this covers up the issue the issue as well. The above footage needed to be stabilized in order to make the pixel dancing effect visible.
I am posting these intermediate results hoping to get some feedback from the forum.
Sharing today a still frame comparision of my current results. Feedback is greatly appreciated!
My setup for scanning Super-8 footage consists of a digital tunable LED light source, combined with a Raspberry Pi HQ-camera. The IR-filter of the HQ camera was changed in order to improve the color definition of redish tones and equipped with a Schneider Componon S 50 mm.
For each frame of the footage, 5 different exposures are taken with the use of the tunable LED source: a highlight scan, a prime scan and three different shadow scans. The difference between these scans is approximately one EV.
Scanning is done in mode 3 of the HQ camera at a resolution of 2016 x 1512 px. The Schneider lens is operated at f-stop 4.7 which supposedly gives the best overall image quality.
The 5 exposures are fused into a single output image via the classical exposure fusion algorithm descriped first by Mertens. After exposure fusion, a noise reduction algorithm utilizing avisynth’s processing pipeline is used to reduce film grain and sharpen the image slightly.
To illustrate the process further, here’s a cut-out of the prime scan of a single frame:
While this frame is not really challenging in terms of the exposure range, a few burned-out parts can be noticed, especially in the river part. Film grain is quite visible, however, it appears slightly blurry. At least not razor sharp. That might be related to using an integrated sphere as the light source (very diffuse illumination) and the scan resolution employed (2016 x 1515 px only).
Here is the current output of the processing pipeline
adjusted to be similar in appearance to the prime scan (basically a contrast adjustment, with a little gamma push (1.4)). I think the overall image quality has improved, especially noticable in the darker shadow areas of the image. Of course, some highlights were added into the image as well; on the vases, some areas are simply blown out in the original footage, so no recovery was possible here. Film grain has been reduced as well with respect to the original scan.
While the restoration results for a single frame are quite satisfactory, the restoration results from a whole sequence are displaying some pixel dancing, as described in my first post above.
Any ideas and comments would be welcomed!
Here’s for reference the full scan of the example frame (the “prime scan”):
(well, not exactly. The forum software scales this down from the original resolution. I included in a post below download-links with the full resolution)
The Raspberry Pi HQ camera is running (for timing reasons) in video mode. So it’s delivering an MJEPG-stream to the server program running on the Raspberry Pi. The MJPEG-stream are just JPEGs, in this case RGB 8bit/channel images with a quality setting of 95. The camera operates in Mode 3 (no binning).
For each frame, 5 different exposures are taken with the help of a tunable LED light (12 bit precision). These exposures are approximately spaced 1 EV apart.
The camera operates during the whole scanning process continously with fixed settings. Client software on a WIN10 PC stores the received frames into several directories, one for each exposure setting.
The five exposures for a single frame (RGB JPEG, 8 bit/channel) are run through a rather complicated exposure fusion script written in Python. After reading the JPEGs from disk, the images are internally converted to float images (0.0=black, 1.0=full white) before any processing occurs. All internal processing use float values. So, the output of the exposure fusion is a floating point image as well. However, for space reasons, the image is converted to a RGB 16 bit/channel PNG image. For this, a fixed mapping with sufficient headroom is used. That is basically the reason the above example image (“restored frame”) looks rather dull.
I experimented with OpenEXR and the like, but did not notice any visual improvement, just more waste of disk space (and slowing down in turn read- and write-times).
The next processing step utilizes the avisynth environment. Even so the 16 bit/channel images can be read by the avisynth software, so far I was not able to keep the implemented processing pipeline @16 bit. So the result of the avisynth script (the above described image recovery solution) is currently only output as RGB 8bit/channel PNG images. (The avisyth script is opened in VirtualDub and this program can output image sequences directly.)
Those RGB 8bit/channel images are finally piped into daVinci Resolve for editing, camera stabilization and color-grading. DaVinci Resolve is also used to output the final video file.
So: during all intermediate processing the film is stored as a sequences of single images in a directory or several directories. Only at the very end of the whole pipeline, a video encode is happening.
There are other approaches, like for example @dgalland, who uses for intermediate storages a video file format combined with a lossless codec. That is probably just a matter of taste.
Ideally, I would like to keep the whole processing pipeline in floating point format. As it seems that I have exhausted at this point in time all the possibilities available in the avisynth-based motion estimation (there are a lot of sometimes rather undocumented parameters), and because the avisynth-script is also the bottleneck with respect to bit-depth, I am currently considering to implement this script (the restoration script) in Python as well.
@cpixip We have similar configurations and problems but sometimes different solutions.
HDR framerate mode and resolution
The idea of doing HDR with variable lighting is interesting (but a bit more complex than just varying the exposure time). What is really its advantage, you still have to let 3 frames pass after a change to get the right one like after a shutter change ?
So how many frames in total to make your 5 exposures and what resulting fps?
This leads us to the resolution and modes of the HQ camera.
With my application I can measure a maximum fps (capture in python, video mode, jpeg, without network send or processing), I get the following values:
Mode 3 4056x3040 → 3fps
Mode 3 4056x3040 resized 2028x1520 → 9fps
Mode 2 2028x1520 ->13fps
Mode 1 1920x1080 ->19 fps
Obviously it would be better to use mode 3 the only non binned mode but the fps is really too bad especially if you want to do HDR, the HQ camera is really too slow in full resolution. Personally I made my capture in mode 1 1920x1080 resized to 1500x1080 by adjusting the optics not to have unnecessary border.
Auto exposure or not ?
Auto exposure is often criticized by those who think that it destroys the exposure balance of the film. This is true of course for a professional film whose exposure has been carefully worked out. But in an amateur film there are very dark or very light scenes that need to be recovered, and this will not be totally possible in post processing.In this case auto-exposure is very useful, it also allows to limit to three images to do the HDR.
Post Processing
I do the whole thing in avisynth in the order
stabilization (virtual dub plugin)
clearing and degrain,
sharpening, balance, equalization
With an intermediate looseless codec
Then some color adjustments in the NLE editor
For your still images, we don’t know how the film is but I think it should be better, are you really sure of your focus ? I think there are some artifacts in the second image and also a sharpening problem on the edges ?
For the sequence, I did not understand at all your explanations on the origin of the “dancing” effect in the areas where there is grain, in any case I did not see it in my films. Maybe you can send me a short clip of your original clip so that I can process it with my scripts ?
One possibility for the dancing pixels would be compression artifacts early/upstream in the workflow. These may be ok on the resulting 8 bit JPEG files, but would be enhanced and more visible after the processing.
I experienced something similar when doing JPEG frame sequences (24MP 12 bit source down to 24MP 8 bit JPEG). I also used Resolve, and had VirtualDub2 as intermediate step for Neat.
In my case, I switched to raw files (NEFF 12bit is what the camera put out) and used TIFF for the intermediate files, and when I got to Resolve the artifacts were gone.
One, that I can think off, is to maintain the sensor camera color balance the same, since exposure/speed would not change.
But the trade is to have a tunable (dimmable) light source that maintains balance.
I am switching from a DSLR to the Rpi HQ, just starting to learn on the sensor. Thank you for the modes/fps it is helpful to understand the capabilities.
Well, I started actually out with varying the camera’s exposure setting for the different exposures.
However, at least with the old Broadcom stack, all Raspberry Pi cameras (v1/v2/HQ) needed a too long time to settle to the requested exposure value. (Here (second image in that post) is an example of how long it can take for the exposure to stabilize. This is actually not from a Raspberry Pi camera, but very typical for those as well.)
In the end I switched to just let the camera run continously, without changing any setting at all, switching off as much of the “auto”-functions as possible.
Well, I get 10 fps per second raw frame rate, using mode 3. That is actually the maximal frame rate you can achieve in this mode. I am working with a resolution of 2016 x 1512, which is slightly less than the one you quoted. All these images are transfered in the live preview to a Win10 PC, requiring a LAN-bandwidth of 130 Mbit/sec.
The actual capture and transfer of the five different exposures takes about 2.20 to 2.30 sec in total. This is because in capture mode, not all frames delivered by the camera are transfered to the Win10 PC. First, because of the (bad) mechanical design of my scanner, I have to wait 0.55 secs after a frame advance for things to settle down mechanically. Furthermore, because I have not yet synchronized the tunable LED source with the frame capture, I simply wait additional 0.25 secs after switching the illumination amplitude before capturing the next exposure and sending it to the client. This reduces the required LAN-bandwidth to about 25 Mbit/sec.
In principle it would be possible to connect a frame trigger signal from the HQ camera (available on a secondary contact pad) and speed up the scanning process by synching LED and camera switching - so far, I have not bothered to try out this idea.
The full capture of the available dynamic range of Kodachrome Super-8 film stock is difficult to achieve with only three exposures - in this case you will indeed need some automatic exposure compensation to get most of the data. And you will need to space the different exposures farther appart than the EV-spacing I am using of about 1 EV to capture highlights and deep shadows. With five exposures, I am able to run the scan with constant settings, no matter what the material throws upon the scanner. One further advantage when using closely spaced exposures is camera noise reduction happening during exposure fusion. Here are some more examples of five exposures used for exposure fusion. Some of them might be really difficult to capture with a three exposure setup and auto exposure.
Well, that might be. On the other hand, dirt and the like are imaged quite sharply and are well-defined on the scans. I have uploaded the original prime scan as well as the exposure fusion and the restoration result of the frame depicted above.
Well, this is an interesting remark and certainly a possibility. However, the JPEG artefacts are very minor with the HQ camera operating at quality setting of 95. I checked that.
For speed reasons, I can not really switch to another image format as the only other, “better” format would be the full raw format. In fact, I tried this and compared scans with raw images to the image quality of the JPEGs coming out of the video port of the HQ cam. Not too much difference at my settings. But maybe my raw processing was not really up to the task…
The motion estimation algorithms are actutally working on the exposure fusion results. After exposure fusion, no JPEG artifacts are any longer present in the data, they are averaged over during the exposure fusion.However, the noise from film grain is still there. I am afraid that this is the main cause of the problem. So I am currently looking into better ways to prefilter selectively the source files before motion estimation to improve things. But progress is slow.
Indeed. Neither the exposure time (1/32), nor digital (1.0) or analog gain (1.2) are ever touched during scanning. Also, the color balance is kept at fixed values red = blue = 1.67 (this is an unusual color balance for the Raspberry Pi HQ camera, because I replaced the stock IR-filter with another one. Long story.)
@cpixip but @PM490 consider this if you come from a DSLR
but consider this if you come from a DSLR
We all agree that when capturing, a shutter speed change is not immediately reflected and that you have to ignore a few frames before you get the one with the desired exposure value. This is due to the fact that the Pi camera is not a DSLR but rather a video camera that once initialized continuously sends images to the ISP. When an application “captures” an image it gets the current image at the output of this pipeline. Even if the processing is reduced to the minimum without auto functions (awb, shutter,…) you have to wait 3 frames to see the change of exposure. It takes longer of course if there is a feedback and some processing in the pipeline, for example it takes at least 8 frames to calculate an automatic exposure. So I think there is no reason why it should be different when you change your lighting, you say you wait 0.25s at 10fps, we are not far from 3 frames.
For HDR 3 or 5 in practice I do not notice any difference. The dynamic range of the HQ camera is not bad (it was quite different with the V1), HDR is mainly used to avoid burnt whites, just make sure that the dark image is largely underexposed, I go to -4EV.
For the focus it’s really very sensitive, I use a micrometer sliding table and I calculate a numerical
value of the focus quality. The adjustment must be accurate to within 0.1mm.
Finally for the dancing grain it is possible to send me the image sequence that I see if there is a difference with my avisynth scripts ?
@dgalland - you have a sharp eye! Actually, while rereading our discussion, I noticed that at one point in time I switched from the original maxial mode 3 resolution of 2028 x 1520 px to a slightly lower resolution of 2016 x 1512 px.
I cannot remember why and when I introduced this change. Here’s an enlarged view of a scan near the sprocket hole with resolution 2016 x 1512 px:
Well, I think the difference in sharpness is quite visible. Seems that the Raspberry Pi image stack does always a zooming operation, even when a simple cut-out operation would be sufficient.
… while enjoying the pleasure of blown-up enlargements out of tiny Super-8 frames, here’s another example of the still image performance of my approach (capturing 5 different exposures spaced 1 EV apart, exposure fusing into an intermediate 16 bit frames, degraining the footage and sharpening):
The sharpening might be a little bit overdone (note the pronounced edge between dark tunnel and the bright dress of the child) but I like the improved definition on the faces of the people as well as the better visibility of the cracks between the stones. Actually, in those high-contrast areas, the “pixel dancing” is not noticable at all - this is only a problem in low-contrast areas where the film grain outpowers the image structure.
I don’t understand why you call the darker scans “higlight” and vice versa! For me three images would have been enough to ensure the result and the darker image could have been even darker.
Concerning the resolution and modes, yes, it is necessary to limit as much as possible the resize, that’s why I scan directly in mode 1 1500x1080, the only resize will be the one that will take place during stabilization.
I think you are making a confusion, mode 3 is the full non-binned mode with a maximum resolution of 4056x3040, it’s the mode 2 binned which has a maximum resolution of 2028x1520. Do you use mode 3 or mode 2 ?
The mode determines the resolution that comes from the sensor, then changing this resolution or defining a ROI causes a resize (not a crop)
So if you use mode 3 with a resolution of 2028x1520 there is a resize. I don’t know if the result is better than the mode 2 binned 2028*1520, you should make the comparison.
If you don’t specify the mode (mode=0) it is chosen automatically depending on the resolution and framerate.
I also noticed a curious thing when you have chosen the mode there is a maximum framerate that you can get in the application (see my table above with the experimental values). It is important to ask for this value, for example 19fps and you will get 19fps but if you ask for more, 25 fps for example, you will get less than 19!
Sharpening is a tricky problem, with avisynth there is a videofred recipe that gives an excellent result, something like this:
sharpened=source.unsharpmask(30,3,0).blur(0.8).unsharpmask(50,2,0).blur(0.8)
try it !
Well, I certainly agree that you need to wait at least 3 images until the exposure value has stabilized. However, I noticed with various different sensors a drift requiring much longer waits until the exposure had stabilized. Actually, this temporal behavior was different depending on what the combination of initial exposure vs. the target exposure was during testing.
These experiments were done long ago, but during that experiments I of course made sure every auto function of the image processing pipeline was switched off. Well, the processing pipelines might have changed in the intermediate time, I do not know the current status. Maybe the cameras react today faster than 2-3 years ago with exposure changes.
Let me remark that when you are using exposure fusion, you do not really need to get precise exposure times. As long as the exposures are consistent from frame to frame, you will not notice anything. The exposure fusion algorithm does actually not care what the real exposures are. This is different when you switch to real HDR work - here exact exposure values are normally required (You can estimate the exposure values after the fact, but that is noticeably more complicated). In case you want to upgrade later to a full HDR workflow, exact exposure values make your life easier.
In any case, the delayed and non-reproducable response when switching exposure times was the reason I abandoned this approach in favor for a tunable LED source.
Also, at least in theory, with a tunable LED source, you do not need to wait 3 frames, as there is no change in the camera parameters at all. The wait times in my approach are connected to the fact that I have not yet synchronized camera and LED source (this will have to wait for the next major update of the scanner).
Initial experiments with 8 bit DACs revealed that the dynamic range would be too low for capturing most Super-8 color reversal material, so I swapped the DACs out for 12 bit ones. Even so, the dynamic range is barely enough; especially towards the lower illumination levels, a single step in digital brightness results in a large difference of illumination. The five different exposure levels spaced 1 EV apart are the maximum I can currently realize with my 12 bit DACs and the LEDs chosen. Limits come from the available LED output (not enough power) and the color changes introduced by varying the current through the LEDs (this is a tricky one: basically, it is connected to the operating temperature of the LED in question. And of course, that temperature changes constantly at a rapid pace during scanning…). Lastly, even a 12 bit DAC is not really precise enough to cover a larger dynamic range than about 5 EVs.
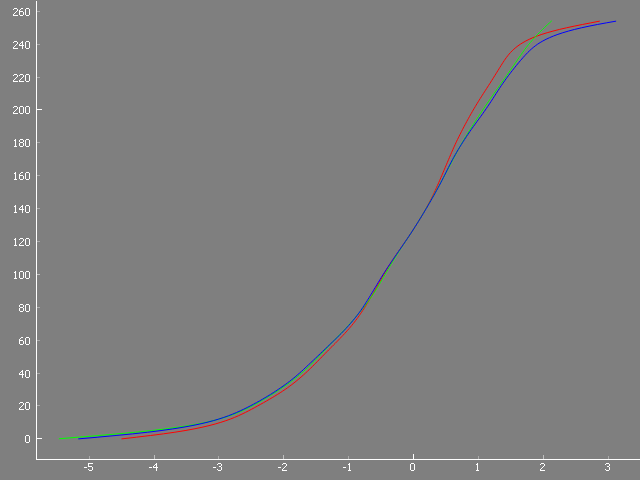
Let’s step back a little bit. In fact, a lot of people do not bother to work with multiple exposures of a single frame, just use a single, well-chosen exposure. In this case, in very dark image areas you notice a reduced contrast with increased noise, and very bright image areas of the frame might easily burn out.
The reason for this can be understood with the help of the diagram below. It shows the response curve of a camera sensor - what pixel value (y-axis) it will output when exposed to a certain brightness (x-axis).
This is a typical camera curve - from cheap webcams to high-end DLSRs (not talking about the raw format here!) you will find a response curve very similar to this one.
Now, there are two parts of this curve where the response curve becomes rather flat; I am talking about the flattened parts of the curve in dark areas (-5 EV to -2 EV) as well as in the bright areas (anything above about 1 EV in the diagram). In these these exposure areas, a rather large difference in exposure will result in only a minor change in bit-values of the output image. Add the sensor noise into this equation and you end up in the dark parts of the image with noisy, rather structureless blob. In the brighter parts of the image, the highlights are squished (the contrast is reduced as well) until the brightest level a 8-bit/channel image can record is reached - everything brighter will just be mapped to the pixel value 255.
Well, ideally, you want to use only the more or less linear part in the gain curve of your camera, in the case below from -2 EV to about 1 EV for scanning. Your image will more or less mirror the original contrast of your frame, nothing gets squished. That is a working range of about 3-4 EVs.
Now, a difference of 3 EV is not enough for scanning color-reversal film. From experience, I think the range of EVs you are dealing with color-reversal film is between 7-9 EVs, depending on the quality of the film stock and the exposure situation. If you you want to capture such a huge dynamic range, you will need to capture several different exposures from a single frame. (The above gain curve is actually the gain curve of the HQ camera, by the way.)
Assuming for the moment that covering 7 EVs is enough (and for various reasons, that is a quite valid assumption), you would be actually fine to capture just two exposures. I have seen people doing just that. The results are fine, but if you look closely at their results, you notice often some faint banding in the areas where the exposure fusion switched from one exposure to the other one.
So, of course, three exposures are even better. And in fact, I have done quite some scans with only three exposures, utilzing a constant LED source and different exposure times. In this case, I spaced the different exposures larger apart, from 1.5 EVs to 2.5 EVs in order to scan as much of the exposure range as possible.
Now, why do I capture currently with five exposures? Well, there are several reasons. Most importantly, a small patch captured perfectly in one exposure is also captured quite decently in the two neighboring exposures. In a finely tuned exposure fusion algorithm, this leads to a reduction of the camera’s noise level, as more information is available and averaged during the calculation this specific pixel. And with my exposure settings (exposure time = 1/32 sec, digital gain = 1.0, analog gain = 1.2, mode 3) the camera is noisy on the pixel level…
Also, the risk of banding is greatly reduced because for most of the image area, the pixel’s output is an average of at least three exposures.
Finally, I just was not satisfied with the image definition I could achieve in the dark areas of the image - I wanted some headroom here for color grading purposes. Both ends of the density spectrum of the film are recorded only by a single exposure - namely the brightest and the darkest exposure in your exposure stack. While with color-reversal film the highlights are not too challenging, as the original film response curve flattens out here anyway, color-reversal film has a rich image structure in the dark parts of the image.
That is the reason I added additional exposures to get more information from the darker parts of the frame - see below…
Well, that’s simple. My naming of the different exposures simply reflects the purposes of the exposures. Here’s the full list:
Highlight Scan: the purpose of this scan is actually to reproduce even the brightest image parts of the frame. Because of this, the exposure for this scan is chosen in such a way that the brightest image areas stay in value below the flat shoulder in the above pictured gain curve. Indeed, if you look at the highlight scan posted above, you can use a color picker in the perforation hole to check: the 8 bit values of each color channel should be in the range of 240 to 250. Of course, the brightest highlight in the actual frame cannot be brighter than the light source itself - so any highlight contained in the frame will be captured faithfully, without saturation of the scanner’s sensor, in the highlight scan.
Prime Scan: this scan is a little brighter (+1 EV) than the highlight scan, so any real highlight in the original frame is burned out in this scan. However, generally this +1EV-scan delivers sufficient image details in most of the image area and that’s why I call it the “Prime Scan”. This scan turns also out to be the most similar to the output result of the exposure fusion algorithm.
Shadow Scan 00:
Shadow Scan 01:
Shadow Scan 02: - all these scans get brighter and brighter in appearance. Their sole purpose is to record as much shadow detail as possible. Since the film emulsion of color-reversal stock goes very deep into the shadows, there is a lot of recoverable detail hidden here. (Note that this is not the case with the burned out highlights - there is no chance of recovering detail lost due to a too bright film exposure. That’s the reason only one highlight scan is present, in contrast to three different shadow scans.)
I hope this makes my naming of the different exposures a little bit more transparent. Some additional information on how I capture frames can be found here and in the posts following this entry. You will note that I never adjust my scanner’s exposure values to the film stock I am scanning - they are referenced to the maximal output the LED light can achieve and stay constant, whatever footage or film stock I am scanning.
Well, no, I am not confused. And yes, I do use mode 3, which indeed has a native resolution of 4056 x 3040 px. Before I explain, let me give you some numbers (this is a Raspberry Pi 4 as server, connected via LAN with a Win10 PC):
Scan Resolution 4056 x 3040 px, (mode 3): 4 fps in live preview, using a LAN-bandwidth of 200 MB/sec. Scan time (5 exposures) for a single frame: 3.5 sec
Scan Resolution 2028 x 1520 px (scaled down from 4056x3040px , mode 3): 10 fps in live preview, using a LAN-bandwidth of 155 MB/sec. Scan time (5 exposures) for a single frame: 2.3 sec
So: I am using the HQ camera in mode 3, but let the camera scale down the original image to a lower resolution. That gives me a temporal advantage of about 1.2 sec per scanned frame, reducing overall scan time for a larger film project (40000 frames → more than half a day).
Here’s a comparision between the image quality obtained with the full-scale 4056 x 3040 px resolution of mode 3
For my taste, the drop in image quality is not so noticeable that it warrants the additional +1 sec delay for each frame scan.
Well, I have uploaded the exposure fusion result of two scenes I used above in the original resolution, but as an encoded video file. The original data would just be too large to store it somewhere (I also have a rather slow internet connection). Anyway, this here should be the download link.
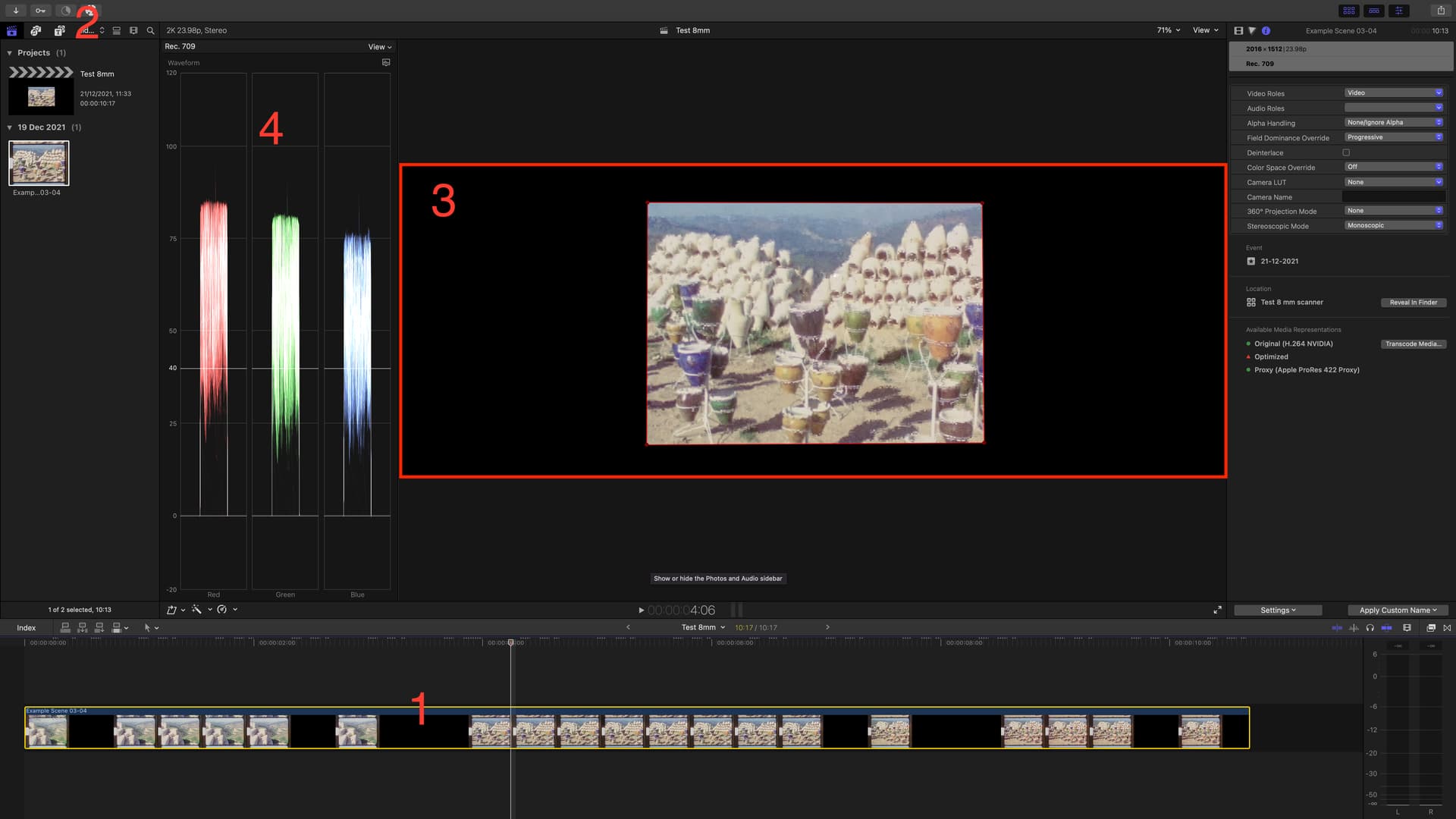
I wanted to see if Final Cut Pro could stabilize the images better.
But when I play the downloaded file on my 17" iMac in the QuickTime Player, I keep getting really weird artifacts at the same frames.
I downloaded the file again and played it successfully in VLC and VirtualDub on my Win10-PC…
Must be some codec misinterpretation; actually, I wanted to upload for @dgalland the raw frames, but living in Germany I only have a 1.8 Mbit/sec internet line, so that was no option for me. Besides, I do not have that much internet space available anyway.
Well, if anybody has better video encoding settings, I am happy to retry it again.
The only difference I can see in the settings is that you have an encoder option. This option is missing on the Mac version of DaVinci Resolve (Studio).
I’m curious what options you have here except NVIDIA.
and encoding time doubles approximately, compared to the “NVIDIA” option. File size is only 50MB, compared to the “NVIDIA” rendering which comes to approximately 150MB.
It gets crazier when I import the clip into Final Cut Pro.
There are multiple black frames in the timeline and the artifacts are the same as in the QuickTime Player
Background rendering goes wild, keeps starting and stopping
The viewer thinks it is some kind of cinemascope format but the inspector gives the correct format
When the image is masked out, you see that the white balance is not correct and there is still a lot that can be corrected in the shadows and highlights















{kind=link}
{kind=link}
{kind=link}