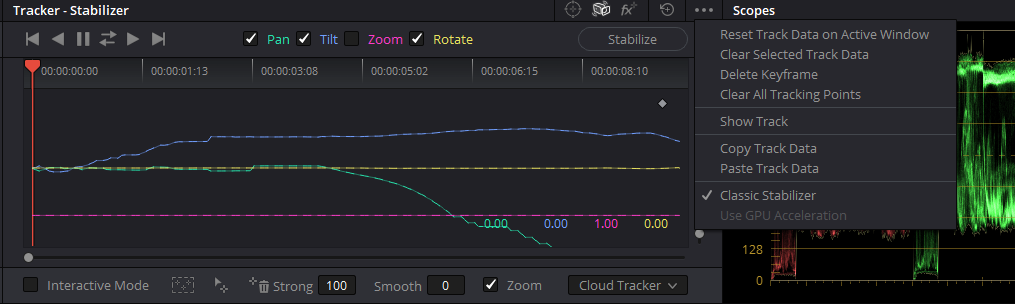
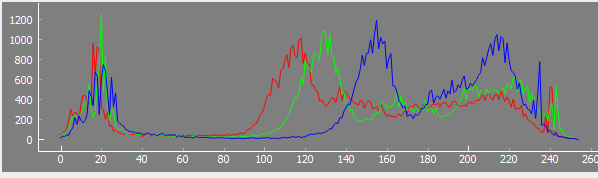
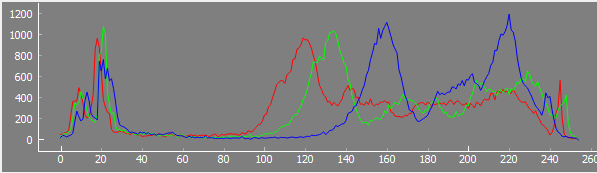
Well, here’s an overview of my current work flow. Remember that my scanner is mechanically quite unstable, so I need to have a few additional processing steps not necessary for other setups.
-
Image Aquisition: a classical Client/Server-Setup, with a Raspberry Pi 4 running as a server, reading from a connected HQ camera, and a WIN10-PC as client, storing the five exposures taken into separate directories. No recoding is happening here, just the “raw” MJPEGs coming from the HQ camera are stored to the disk.
The clip shown above was actually scanned with a different setup, namely a See3CAM_CU135 camera, connected to the RP4 via USB3 - that’s why the resolution of the raw scans is 2880 x 2160 px, not my usual 2016 x 1512 px. The client- and server-software is written in Python, with a little help from opencv and pyqt 5.
-
Exposure-Fusion: again a python-script which reads the five raw exposures and converts them to a HDR/log-like image, as shown in the above clip on the left (“Source”). The exposure fusion script does the following steps in sequence: a) initial sprocket-registration b) subpixel-registration between the five frame exposures (necessary because the frame moves between exposures with my scanning setup) c) exposure fusion and finally d) saving the image data in a separate directory as 16 bit/channel .png-files.
-
Image-Stabilization: here, I was initially using the Deshaker-plugin + VirtualDub2, but I now I am using daVinci Resolve for this task. More details about this below.
-
Enhancement: by using any one of the above mentioned avisynth-scripts, in combination with VirtualDub2. At this point, the images are reduced to 8 bit/channel images again - I haven’t yet succeeded in runinng any avisynth-script with 16 bit/channel (theoretically, it should be possible). That it is still a point on my todo-list to investigate.
-
Cropping/Editing/Dirt-Removal/Color-Grading/Output: again, daVinci Resolve is used here. Note that I only crop the originally overscanned image to the output frame at this very last processing point. This gives me some space for further refinements, like additional image stabilization or other weird stuff I might want to do at that point. For cleaning, I use mostly the “Automatic Dirt Removal” plugin of DaVinci Resolve, sometimes also the more manual “Dust Buster” module. The “Automatic Dirt Removal” module works well most of the time, but it is only available in the paid version.
That’s about it. The reason for the image stabilization (3.) done before the enhancement step is that the motion-estimation algorithms have appreciably less to do than and less of a chance to fail.
As already mentioned, initally I used DeShaker in combination with VirtualDub2, for two reasons: first, it works quite well, and second, I had worked before with this plugin for a long time. But I switched quite a while ago to daVinci Resolve. One reason is that you need to stabilize each scene of your footage separately, for good results. It is a bit cumbersome with VirtualDub and DeShaker to separate the scenes of a whole film, but daVinci Resolve features actually a quite usable scene detection feature for this. Another reason for switching to daVinci Resolve are the two available, quite speedy trackers. One drawback here is that the standard tracker features just three modes, namely “Perspective”, “Similarity” and “Translation”.
Ideally, you would want for the image stabilization only three degrees of freedoms tracked - pan, tilt and rotation. The daVinci-mode “Similarity” would be ideal, but it tracks in addition the “Zoom”-property, which should be avoided at this stage.
So, with the standard tracker selected, your best bet in daVinci is to use the “Translation”-mode for pretracking your footage, with each scene tracked separately. It is good to tune some of the parameters for optimal performance for each scene. For example, “Smooth” lets you adjust how much of the original camera movement is canceled - you want to reduce irregular shaking, but keep the overall movement of the camera. Also, make sure that the “Zoom”-checkbox is unchecked and the timeline resolution is set to the real image resolution (in my case: 2880 x 2160 px), especially when outputting the stabilized frames.
A better daVinci-option for pretracking is probably the older tracking functionality of daVinci, slightly hidden underneath the three bullets on the far right of the tracking window:
Place a checkmark on the second line from below, mark “Classical Stabilizer”. In the tracking window, you can now deselect the “Zoom”-checkbox, and you are all set for tracking. If you leave the “Smooth”-parameter at the default setting of 0, your frame will not move at all after applying the calculated stabilization. This is not what you want - you will need to use a non-zero value here. I use anything between 40 and 90, depending on the scene and my taste.
@PM490: if your base your image processing on opencv algorithms, most of the time you can use images of type np.float. Only a few image processing routines work only on 8 or 16 bit/channel data. So basically all my processing is based on np.float arrays. You will get much more than the 16 bit per channel (either 32 bit or 64 bit float per channel) when using np.floats.
You just need to remember that the results of the exposure fusion algorithm normally overflow the usual float mapping (0.0 = black and 1.0 = pure white). Because of this, I am using the following write function
def writeImg(fileName,img,*para):
minimum, maximum, flip = para
scaler = 0xffff/(maximum-minimum)
if flip:
img = cv2.flip(img,0)
imgOut = np.clip( scaler*(img-minimum),0x00,0xffff).astype(np.uint16)
success, buffer = cv2.imencode(".png", imgOut,[cv2.IMWRITE_PNG_COMPRESSION, 9])
del success
buffer.tofile(fileName)
with the parameters and the write-call
outputMin = -0.30
outputMax = +1.30
writeImg(outputName,image,outputMin,outputMax,false)
Another, more advanced option is to use the OpenImageIO library, which nicely interacts with opencv. This library supports for example the imageformats OpenEXR as well as DPX-files (among many others). It has a Python interface.
I think I have installed that for my python environment simply with (albeit, I am not 100% sure of this)
pip install OpenImageIO
I am using this library mainly for reading .DPX-files like so:
if 'OpenImageIO' in sys.modules and os.path.splitext(self.fileName)[1]=='.dpx' :
io = oiio.ImageInput.open(self.fileName)
if io:
self.inputImage = io.read_image()
io.close()
As I mentioned above, I have not yet succeeded in running any avisynth-script with more than 8 bit/channel. The basic working horse of the scripts are the MVTools2, which should be able to handle higher bit-depths than 8 bit/channel. So far, with my material, I did not observe any issues when working with 8 bit/channel in the final editing/grading stage.
 fine that this worked!
fine that this worked!