– adding here some additional information about delays and cyclic capture. When you request a certain exposure time, libcamera/picamera2 will need quite some time to give you that exposure time back. Here’s the output of an experiment I did about a year ago (so this is an old version of picamera2):
Index - requested : obtained : delta
0 - 2047 : 2032 : 0.031 sec
1 - 2047 : 2032 : 0.034 sec
2 - 2047 : 2032 : 0.034 sec
3 - 2047 : 2032 : 0.044 sec
4 - 2047 : 2032 : 0.031 sec
5 - 2047 : 2032 : 0.034 sec
6 - 2047 : 2032 : 0.034 sec
7 - 2047 : 2032 : 0.044 sec
8 - 2047 : 2032 : 0.031 sec
9 - 2047 : 2032 : 0.034 sec
10 - 977 : 2032 : 0.031 sec
11 - 1953 : 2032 : 0.021 sec
12 - 3906 : 2032 : 0.035 sec
13 - 7813 : 2032 : 0.032 sec
14 - 15625 : 2032 : 0.033 sec
15 - 977 : 2032 : 0.034 sec
16 - 1953 : 2032 : 0.033 sec
17 - 3906 : 2032 : 0.032 sec
18 - 7813 : 2032 : 0.033 sec
19 - 15625 : 2032 : 0.034 sec
20 - 977 : 2032 : 0.037 sec
21 - 1953 : 970 : 0.029 sec
22 - 3906 : 1941 : 0.038 sec
23 - 7813 : 3897 : 0.028 sec
24 - 15625 : 7810 : 0.036 sec
25 - 2047 : 15621 : 0.033 sec
26 - 2047 : 970 : 0.032 sec
27 - 2047 : 1941 : 0.037 sec
28 - 2047 : 3897 : 0.030 sec
29 - 2047 : 7810 : 0.032 sec
30 - 2047 : 15621 : 0.034 sec
31 - 2047 : 970 : 0.033 sec
32 - 2047 : 1941 : 0.036 sec
33 - 2047 : 3897 : 0.031 sec
34 - 2047 : 7810 : 0.034 sec
35 - 2047 : 15621 : 0.035 sec
36 - 2047 : 2032 : 0.031 sec
37 - 2047 : 2032 : 0.034 sec
38 - 2047 : 2032 : 0.034 sec
39 - 2047 : 2032 : 0.044 sec
For frames 0 to 10, the exposure time was fixed at 2047 - but I got only a real exposure time of 2032, the rest “taken care of” by a digital gain larger than 1.0.
At time 10 I request a different exposure time of 977. The first frame with that exposure time arrived only at time 21. That’s the time the request needed to travel down the libcamera pipeline to the camera and back again to picamera’s output routine. Eleven frames is more than a second in the highest resolution mode! Again, I requested 977 and got 970 - close, but not a perfect match.
After time step 10 I cycle through all the exposure values, that is [977,1953,3906,7813] for a few cylces. As you can see, the camera follows that cycle frame by frame. Once I switch back to my base exposure 2047 at time point 25, the camera continues to cycle until time 36 where it delivers again the requested exposure time.
So - in order to get the data of a full exposure stack, in cycle mode you need to wait only for four consecutive frames at most. Provided, you cycle constantly through all exposures. Given, you have no idea which of the four exposure will be the first to show up in the pipeline, but you know that the following three frames will be the other missing exposures. That’s the neat trick of cycling constantly through all required exposure. I got this trick from David Plowman, the developer of picamera2.
Of course, you need to program some logic which will save the incoming data into the appropriate slots of your HDR-stack, and you will need some additional logic to trigger frame advance and wait a little time that all the mechanical vibration have been settled.
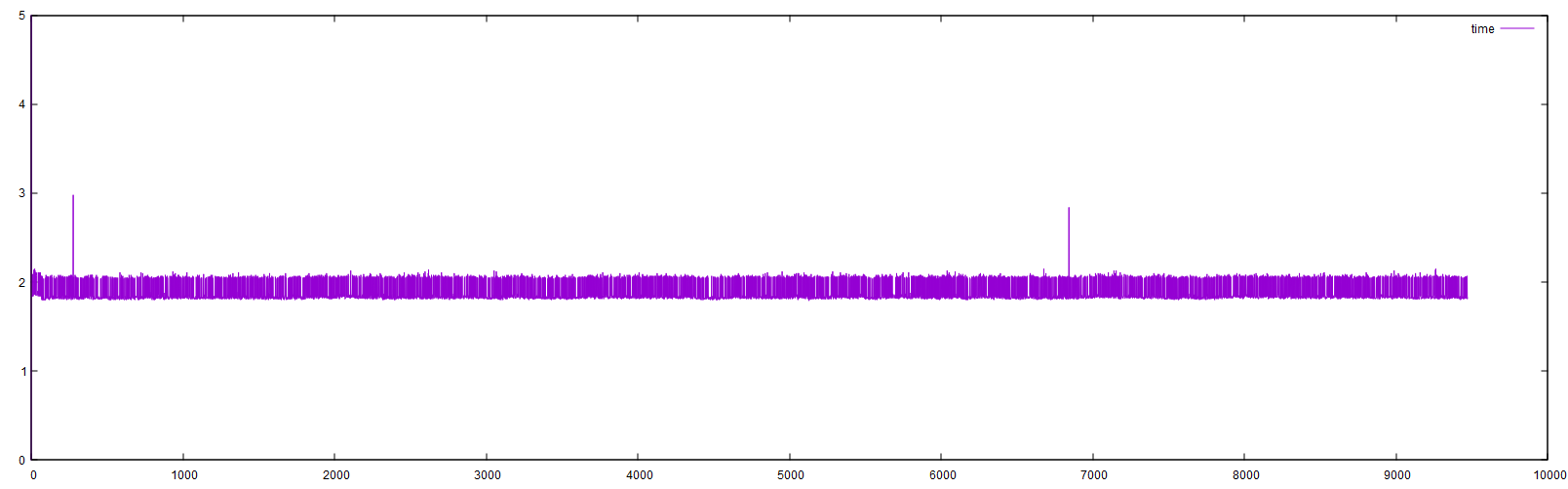
As my scanner is mechanically not very stable (it’s all plastic), my waiting time (time between “trigger of frame advance” until “store next frame in HDR-stack”) is 1 sec; running the HQ sensor at it’s highest resolution gives me a standard frame rate of 10 fps. Nevertheless, capturing a single HDR-stack of a frame takes me on the average between 1.85 and 2.14 sec. Here’s a log-file of such a capture (capture time vs. frame number):
Note that these times include my 1 sec mechanical delay. So the capture would be faster if your mechanical design does not need a long movement delay. Again, this is the result when using the HQ sensor at full resolution setting, i.e., with 10 fps.
Occationally there are spikes where the capture takes noticeably longer, about 3 sec (two in the above plot). Might be related to some syncing issue, but I do not know the real reason. As it does not happen very often, I did not bother to investigate further.