Well, that research will need some more time to finalize… ![]()
But, here’s the current status:
Actually taking raw images is pretty expensive, memory- and speed-wise. A 4056 x 3040 px raw image from the HQ camera in Adobe-format (.dng) will come at a size of slightly less than 24 MB. The jpg-image in the same resolution is less than 0.5 MB. So capturing raw will slow things down.
Furthermore, a single raw file with the maximum bit-depth the HQ camera is supporting, namely 12 bit, is not enough to cover the full dynamic range of color-reversal film stock. So you need a way to fuse several raw images with a basic bit depth of 12 bit and different exposure settings together to obtain a raw image with much higher bit depth. Here are results on a real image with a very large dynamic range (used here because I do not have to take film grain into account) .
Three exposures were taken with 0.002, 0.004 and 0.016 secs of the scene and saved as .dng-files. These single exposures were “fused” in four different ways and gave the following results:

- Top Left: only the raw data from the two exposures with 0.002 and 0.004 secs were fused together. The resulting raw was than “developed” into the single sRGB image presented here.
- Top Right: only the raw data of the two exposures with 0.004 and 0.016 secs were fused (the two brighter exposures). The resulting raw was again developed in the same way as the “Top Left” result.
- Bottom Right: the raw data of all three exposures were fused and developed.
- Bottom Left: all three raw exposures were individually developed into sRGB (jpeg-like) images and these sRGB images were exposure fused via the Mertens algorithm (that is the classical “exposure fusion” way).
Time for a short discussion: Clearly, the “Top Left” image show noticable noise in the dark areas. The “Top Right” result is better, the best result is obtained in the “Bottom Right” corner. The exposure fusion result (“Bottom Left”) is comparable to this, but it shows some noticable glare effects.
These glare effects are due to the way exposure fusion works and can only be avoided by working directly with raw images. In fact, I created this test example especially to show this effect. However, most of the time, this glare effect is not noticable. Here’s an actual film frame calculated the same way as the test image above:

Note that the exposure fusion result (“Bottom Left”) shows more vivid colors and some haze reduction in the far distance. This behaviour is “backed in” the exposure fusion algorithm. But actually, the 3-exposure raw image result (“Bottom Right”) is more true to the actual film frame.
Well, that is my current state of affairs.
At this point in time, I think my old way of doing things, namely capturing several jpgs of a single frame following by classical exposure fusion will give me better results in terms of image quality, as well as capture speed.
So I do not think that I will develop the raw capture stuff further.
Because of the limited dynamic range of raw images (only 12bit), capturing in raw also requires several exposures per frame; while it’s more accurate than exposure fusion of multiple sRGB images, it’s not faster and the visual quality isn’t significantly better.
The next goal in this project is to come up with an own tuning file for the HQ sensor (IMX477) which minimics closely the processing I have applied above – in effect persuade libcamera to do the necessary processing for me. There is still a lot to do.
For example, the gamma-curve of the IMX477 tuning file does not follow rec 709 at all, like the following graphic shows:
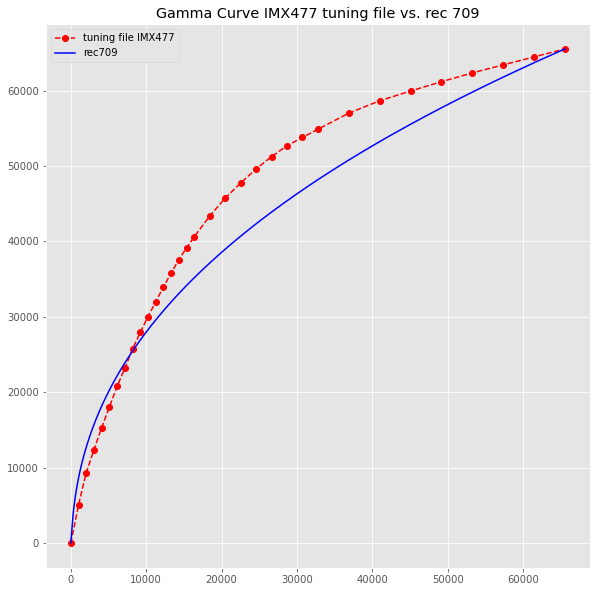
As noted in another thread, the color matrices (ccm) in the original IMX477 tuning file do not work well either. The problem is probably caused by the way these tuning file were created – there is very little information available about this.
However, I think I succeeded in calculating optimal ccms from a given spectral distribution of the illumination and the camera sensor used (in this case the IMX477).
The “development” of the first image above is based on a D65 illuminant, the second one (the film frame) is actually based on the spectral distribution of my 3LED-setup. The first image uses the stock HQ camera, the second image (the film frame) a HQ camera where the IR-block filter has been replaced.
So my current idea is the following:
- use the picamera2/libcamera approach to create “jpg” images with a special tuning file, calculated especially for the illumination source of the film scanner.
- Take 3 to 5 different exposures of each film frame, transfer them to a fast machine for exposure fusion.
- As I now know, white-light LEDs with a high CRI will give me better results than my current 3-LED setup. So the red, green and blue LEDs of my scanner will be replaced by white-light LEDs. As I could only source Osram Oslon SSL80 with the form factor I need, these will be used. They are not perfect, but listed with a CRI between 90-95.
- Also, I now know that a previous experiment (the replacement of the stock IR-filter with a better one) actually results in worse color rendering. So the current camera (with a flat response curve IR-filter) will be replaced by a stock camera, employing the standard Hoya CM500 IR-block filter.
Stay tuned…