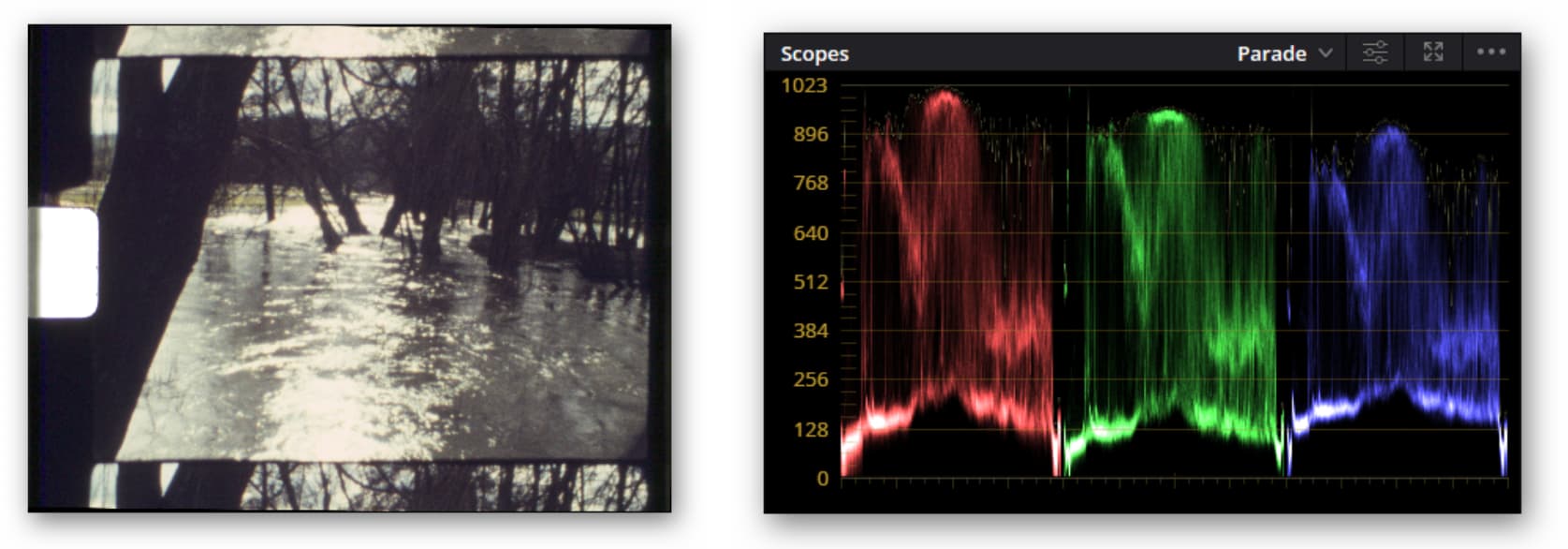
Well, this thread started out as a comparision between the Pi HQ camera sensor and a full-frame DSLR. Let me try to summarize some things about the HQ sensor and the associated software environment.
Over the years, the Pi guys have offered several different types of sensors and quite different software libraries as well. In summary: do not bother with any of these sensor types other than the HQ sensor and: be aware of some weird things happening under the hood of the software (libcamera/picamera2). I will try to elaborate on all these things.
S8 footage
Before we go further, let us remind ourselves about our target to digitze: we are considering only S8 color-reversal film stock.
The camera frame of S8 footage has a size of about 5.7 x 4.3 mm. Though usually, a slightly wider frame is exposed. Depending on the film stock (Kodachrome, Agfachrome, etc) and the type of camera used in the old days (Leicina, Bauer, Chinon, etc) , the effective image resolution might vary from less than 480p (SD) to 1080p (HD). The typical dynamic range of a well-lid scene is around 11-12 bits with color-reversal film stock, whereas strong contrast scenes can exceed 14 bit dynamic range.
The Hardware
The first camera the Pi guys introduced was the V1 camera, followed by V2 and V3 versions. All of these cameras are based on mobile phone technology and should be avoided for telecine work. The main reason: the sensors used in these cameras feature a microlens array which is matched to the focal length of the attached lens. If you swap that lens with a lens of different focal length (which you have to for telecine work), the mismatch creates a magenta color cast in the image center which is not recoverable.
So in the end, there only are two units available from the Pi guys which might be of use for scanning S8 film. Both types (GS/HQ) do not come with a pre-attached lens, instead, they feature a standard C/CS-mount.
The GS (global shutter) sensor is nice, but the maximal resolution of 1456 x 1088 px is not really high enough to scan the resolution of S8 film stock well. So the only option available for a decent telecine within the Pi offerings is the HQ sensor.
The HQ sensor, more correctly the IMX477, was developed by Sony for consumer camcorder applications. Think of the typical HD camcorder which is able to grab occationally also slightly higher resolution still images. Clearly, at that level, we are not at the end of the line with respect to sensor quality. DSLRs come with much larger sensors, like APS-C or even full-frame sensors. Especially the noise characteristics improve dramatically with larger sensor sizes.
The HQ Sensor
The HQ sensor features a maximal resolution of 4056 x 3040 px (let’s call this 4k) as well as lower resolution modes. Since the HQ sensor uses only 2 of 4 possible CSI-lanes, the 4k mode can only deliver maximal 10 fps.
There are lower resolution modes available which deliver faster frame rates, but: do not use them. Especially the 2k mode (in the image below labeled “HQ Cam Mode 2”) uses a badly designed scale-down filter, combined with some annoying sharpening. If you want to work at the 2k res, operate instead the HQ sensor at the 4k mode (labeled “HQ Cam Mode 3” in the image below) and scale down to 2k.
To really see the differences between these modes, view this image
at full size.
As mentioned above, the HQ sensor is of the “camcorder” quality. Which means that the noise behaviour is far inferior compared to an APS-C or full frame sensor. In addition, various people have noticed that there is obviously some noise processing ongoing already at the sensor level. This results in funny horizontal noise stripes, with increasing noise intensity from the left to the right side of the sensor.
Here’s my attempt to visualize this:
Shown above is the green channel of a severly underexposed image, pushed 6 EVs up to make that noise/image more visible.
If that noise structure bothers you, you better switch from the ~ 50€ HQ sensor to something slightly more expensive. In reality, it probably does not matter to much, as the film grain of S8 footage will cover up the sensor’s noise.
Now, looking at the dimensions of the S8 frame (5.7 x 4.3 mm) and the HQ sensor (6.3 x 4.7 mm), one can notice that they are very similar in size. So, allowing a little overscan area, one arrives at an approximately 1:1 imaging setup. This brings me to the next section.
The lens
First of all, a 1:1 imaging setup is probably the simplest one to realize. In the thin-lens approximation (I come back to this later) you get a 1:1 magnification if you place the object two times the focal length of the lens away. To get the object sharp on the sensor, you need to position the sensor on the other side of the lens at the same distance away, namely two times the focal length of the lens.
Now, real lenses are a little bit more complicated than thin lenses. For starters, they have principle planes and all that. So this arrangement will only yield you an approximation for further refinement.
Another thing one has to consider is the design range of the lens you are using. Typical photographic lenses are optimized for the imaging of objects rather far away. Simultaniously, the sensor is very close to the lens, about one focal length. Clearly, our 1:1 setup with its lens-sensor and object-lens distance of two focal lengths is not matching this design.
However, there is a breed of lenses which has more closely matching design ranges: enlarger lenses. As I operated in the last century my own color lab and still had a bunch of different Schneider Componon-S lenses in my box, this was my obvious choice. Specifically, the 50mm/2.8 - which is easy to get on ebay, for example. Of course, other enlarger lenses are also a valid options.
Now, every lens has an interesting behaviour with respect to the f-stop value. For ease of production, lens surfaces are usually manufactured as spherical surfaces. This is however not the optimal shape. Especially the outer regions of any lens tend to screw the quality of your image. At first sight, there is an easy solution. Just close the aperature (that is, work with higher f-stops) so only the “good” center parts of the lens(es) are used.
This is indeed a working solution, up to a point. If you change the aperature of the Schneider 50 mm from the largest value of 2.8 to, say, 4.8, the image gets less blurry.
But: the is another process working here which spoils that fun. Light is basically a wave phenomen, and if you close the aperature too much, diffraction effects will start to appear. That is: closing the aperature further makes the image more blurry again. Continueing with the Schneider 50 mm, at an f-stop of 8 diffraction starts to degrade the image.
So there is a sweet spot somewhere in the middle of the f-stop range of your lens. Where that specific sweet spot is located depends on your setup. For example, in my scanner setup, it is difficult to align the sensor’s surface really parallel to the film gate. I usually end up with a slight misalignment. So I tend to work with a slightly larger f-stop value than the optimal one, as this gives me a larger depth of field.
Usually, aperatures are also used to regulate the amount of light falling onto the sensor, that is, the exposure. Note that this topic is of no concern in our application. The f-stop is solely selected on the basis of maximal sharpness. Indeed, the exposure should never be adjusted with the f-stop of the lens. Adust instead your light source (if possible) or the exposure time of your sensor.
The Software
The HQ sensor can be handled with various software approaches. By far the easiest way is the libcamera/picamer2 combination, which uses Python as programming language. And I say this as an old C/C++ programer…
Note that libcamera as well as picamera2 are constantly evolving. Picamera2 is still labeled as “beta” and probably will stay in this state for quite some time. So be careful when updating the libraries or your operating system: you might end up with a non-working scanner.
The design goal of both of these libraries is to mimic for the average user the performance and ease of use, similar to mobile phone cameras. Putting that differently: a lot of automatic algorithms are working in the background, quietly adjusting things for you. That’s great if you do not exactly know what you are doing, but somewhat disabling if you know.
Specifically, you will encounter the following challenges:
- there are things you will never be able to switch off in software. An example is the on-sensor defect pixel correction (DCP) which you can only influence via the command line, out of program scope.
- other things you are not able to change via software include things which you only can influence by editing the tuning file for your sensor. An example is the
ce_enable parameter in the tuning file. Setting it to zero switches off an automatic contrast algorithm running in the background.
- other things you can set and modify within the picamera2 context, but sometimes the soft- as well as the hardware makes educated guesses in the background about what you really want to achieve. An example is the resolution the sensor is operating at. You might think you are requesting the 4k mode, but picamera2 might decide instead that the 2k mode is more appropriate. Something like this might happen if you operate at 3k - instead of switching to 4k and scaling down, you might end up in operating at 2k blowing up this resolution to 3k. Obviously something one wants to avoid in a telecine application.
- finally, some settings have side effects, occationally only on certain hardware. For example, the RP5 which works by default in a “visually lossless” raw format. That’s fine if you only want to store .jpgs or so, but it spells desaster if you want to save the original raw data of the sensor. In this case, without telling you, the lossy compressed raw data (which is inferior to the sensor’s original raw data) is uncompressed and saved. Nobody will tell you, except that your program takes about an additional second for this step…
Well, more on all of that later in this post. Before that, we need to look at the various output formats one can work with.
What to capture
Most of the well-exposed color-reversal S8 footage has a dynamic range of about 12 bit. That fits nicely with the maximal dynamic range of the HQ sensor which is also 12 bits. But beware: there are also modes available which operate only at 10 bit, and the RP5’s default mode (the “visually lossless” one) works only in 8 bit, albeit non-linear encoded. You certainly want to make sure that you are operating at the highest dynamic range possible, that is 12 bit.
While 12 bit works ok for most footage, high contrast scenes exceed that range (that depends mainly on the film material; Kodachrome is especially challenging). One way to counteract this is to capture actually not one, but a whole stack of several different exposures from each single frame, from very dark exposures (for capturing the highlights) to very bright ones (for capturing structure in the dark shadows). Before we go into technical details, let’s fix some nomenclature:
- RAW: that is the raw data as directly recorded by the sensor. Four color channels, Red, Green1, Green2 and Blue. For the HQ sensor, this kind of data has a bit depth of 12 bits. The data is linear with respect to the number of photons received by the sensor. Without further processing (“development” by a raw converter), it is not viewable by a human observer.
- LDR: this is short for low dynamic range image. It has a bit depth of only 8 bit (or 16 bit) and is displayable on a normal computer screen. In other words, it is viewable by a human observer. To achieve this, some “color science” and at least a contrast curve (say, rec709) needs to be applied to the raw image from the sensor. An LDR features only three color channels, namely red, green and blue. You will get this from libcamera/picamera2 if you request/store a .jpg or .png format.
- HDR: this is a high dynamic range image. A HDR is usually encoded in a floating point format and thus has an unlimited dynamic range. It is usually neither displayable on a normal monitor, nor viewable by human beings. For this, a tone-mapping operation has to be applied, which converts the HDR into a LDR. Note that in normal internet talk, an LDR created via tone-mapping from a HDR is often also called a “hdr-image”; well, it is not.
How to capture
In the early days, there was actually no way to capture any raw data from the Pi hardware. You could only capture LDRs as .jpg or .png. Remember, such data has a contrast curve applied in order to squeeze the image information into the limited dynamic range of 8/16 bit. Because of this, highlights were blown out and texture in the shadows gone.
So at that time the choice was clear: one needed to capture a stack of LDRs with different exposures and combine them afterwards. In fact, once you have such an LDR-stack, there are two quite different options for further processing: Debevec’s way and Mertens’ way. Both are available within the opencv library (though I work with my own implementations):
- Debevec’s way: here, the LDR stack gets analyzed in order to recover the gain curves your camera applied to the original RAW sensor data to create your LDRs. Once that task has been achieved, the stack of LDR images can be remapped back to something similar to the raw values your sensor recorded. Each individual LDR covers only a certain band of intensity values. However, by appropriate combination, the full dynamic range of the original frame can be recovered. In principle, you are unlimited with respect to the dynamic range the computed HDR can represent. Of course, you need to convert (squash) this huge dynamic range into a LDR for creating your output video. This process is called tone-mapping and there is an abundance of different algorithms available for this. The main reason: it’s not that trivial to do this.
- Mertens’ way, also called “exposure fusion”: Here, by a process imitating how the human visual system is working, the LDR-stack is directly transformed into an output LDR. There is never a HDR recovered in this process. In essence, exposure fusion is done by local contrast adaptions. As it turns out, this can in fact even enhance some footage (bad exposure by the S8-camera, for example). A further advantage: from the output LDR of the exposure fusion algorithm you can directly go on to create your digital copy of the S8 footage.
There is however a slight drawback to these approaches. Both operate indepently on each of the color channels. Especially within the exposure fusion context (Mertens) it is difficult to get the colors right because the independent contrast equalization operates and changes colors locally.
Now, as the libcamera/picamera2 software evolved, the possibility of capturing RAW data surfaced. Initially, and even today, the implementation is not 100% correct, but at the time of this post (Sep 24), it is usable. Specifically, the .dng-files created by picamera2 can directly be read by DaVinci Resolve.
Two issues remain when working with .dng-files. Both are related. For starters and as discussed above, the noise of the tiny sensor is noticable. However, especially old S8 filmstock (for example Agfachrome from the seventies of the last century) has such a strong film grain that the noise of the HQ sensor becomes irrelevant. More so if you employ spatio-temporal noise removal - which I do, as I am more concerned about the content than the appearance of old S8 footage. Besides, even without spatio-temporal noise processing, the noise of the HQ appears mostly in rather dark image areas. As these areas end up in the final video anyway as rather dark areas, the increased noise there is barely visible.
So - at this point in time, I would recommend capturing the footage as .dng-files. While working with multiple exposures has its merits, the additional amount of time needed for the various captures, including additional software processing required (you might need to align the various exposures before fusion or HDR calculation because your camera or film has moved a little bit during the different exposures) does not give you such a great advantage in terms of quality that capturing LDRs outperform the ease of working directly with RAW data.So, it’s now time to examine the little traps hidden in working with raws…
Capturing RAWs - Example implementation
As indicated above, there are some things to consider when working with RAW data. The RAW format which the picamera2 lib is delivering is based on Adobe’s .dng-standard. This is a spec for a universal raw format, intended as an alternative to different camera manufacturer’s proprietary raw formats. Accordingly, it is a rather complex format. It features information about the color science of the camera as well as possibly other information, lens distortion and other stuff. A raw developer software should be using all of this information to derive a developed image from the dng.
The picamera2-implementation of the .dng-writer works more on the simple side of things.
Here’s an example of all the data hidden in a picamera2. .dng-file:
---- File ----
File Name : RAW_00022.dng
Directory : G:/capture/00_RAW
File Size : 24 MB
File Modification Date/Time : 2024:05:25 08:25:06+02:00
File Access Date/Time : 2024:05:25 08:25:06+02:00
File Creation Date/Time : 2024:05:25 08:25:04+02:00
File Permissions : rw-rw-rw-
File Type : DNG
File Type Extension : dng
MIME Type : image/x-adobe-dng
Exif Byte Order : Little-endian (Intel, II)
---- EXIF ----
Subfile Type : Full-resolution image
Image Width : 4056
Image Height : 3040
Bits Per Sample : 16
Compression : Uncompressed
Photometric Interpretation : Color Filter Array
Make : RaspberryPi
Camera Model Name : PiDNG / PiCamera2
Orientation : Horizontal (normal)
Samples Per Pixel : 1
Software : PiDNG
Tile Width : 4056
Tile Length : 3040
Tile Offsets : 760
Tile Byte Counts : 24660480
CFA Repeat Pattern Dim : 2 2
CFA Pattern 2 : 1 0 2 1
Exposure Time : 1/217
ISO : 100
DNG Version : 1.4.0.0
DNG Backward Version : 1.0.0.0
Black Level Repeat Dim : 2 2
Black Level : 4096 4096 4096 4096
White Level : 65535
Color Matrix 1 : 0.5357 -0.0917 -0.0632 -0.4086 1.2284 0.1524 -0.1115 0.2109 0.3415
Camera Calibration 1 : 1 0 0 0 1 0 0 0 1
Camera Calibration 2 : 1 0 0 0 1 0 0 0 1
As Shot Neutral : 0.3448275862 1 0.4739561117
Baseline Exposure : 1
Calibration Illuminant 1 : D65
Raw Data Unique ID : 31323139303036313939303030
Profile Name : PiDNG / PiCamera2 Profile
Profile Embed Policy : No Restrictions
---- Composite ----
CFA Pattern : [Green,Red][Blue,Green]
Image Size : 4056x3040
Megapixels : 12.3
Shutter Speed : 1/217
Bascially, only the color science is embedded in the dng, distributed over various tags like
Black Level, Color Matrix 1, Calibration Illuminant 1 and As Shot Neutral. Specifically this color science is of utmost importance for deriving a usuable image from the raw digital data of the .dng-file.
Color Science of Raw Files
The most common .dng-format uses two different color matrices (CM1 and CM2), one for the cool end of the spectrum, one for the warmer color part. Where these color matrices are located in this range is actually indicated by Calibration Illuminant tags.
The actual color matrix used in decoding the raw data into real colors is normally calculated from the As Shot Neutral tag (which codes the color temperature of the scene) and the two color matrices embedded via a special interpolation. (I am simplifying here: it’s even more complicated, because normally there are two additional forward matrices included.)
Well, as can be seen from the tag-listing above, the .dng-file created by picameras features only a single Color Matrix 1. The data contained in this single matrix should usually directly used to derive colors from the RAW data of the .dng, at least if you select something like “Camera Standard” in your software. Be sure to check how your your software performs.
You’re fine if you use DaVinci Resolve for reading the .dng-file. DaVinci works out of the box.
Now there’s one important point to note here is: this matrix is calculated by libcamera/picamera2 on the basis of the color matrices embedded in the tuning file you are using. So you will get different colors in your raw converter (or any other program which can directly process .dng-files, like DaVinci) if you choose the standard HQ tuning file (“imx477.json”) versus the alternative one (“imx477_scientific.json”). I would strongly suggest to use the later.
Example Program
Remember that we already talked about the RP5’s “visual lossless” raw format? And about the inferiour performance of the 2k resolution versus the 4k one? Here’s now a simple script which sets up the HQ sensor in the correct way, that is, with 4K uncompressed raw:
from pprint import *
import time
from picamera2 import Picamera2
if True:
# load alternative tuning file
tuning = Picamera2.load_tuning_file('imx477_scientific.json')
picam2 = Picamera2(tuning=tuning)
else:
# start with standard tuning file
picam2 = Picamera2()
# directly configuring the raw format; old, but backward compatible
raw = {'size': (4056, 3040)}
# we do not use main; 'RGB888' is memory conservative
main = {'size': raw['size'], 'format': 'RGB888'}
# create a config with defaults
config = picam2.create_still_configuration()
# increase buffer count (RP4 -> 4 buffers/RP 5 -> 6 buffers)
config['buffer_count'] = 4
# we do not use the queue - that is, a request starts capturing
config['queue'] = False
# full frame, uncompressed raw -> max. 10 fps
config['raw'] = {"size":(4056, 3040),"format":"SRGGB12"}
# we actually do not use 'main', but we set it to the less memory intense 'RGB888'
config['main'] = {"size":(4056, 3040),'format':'RGB888'}
# no noise reduction
config['controls']['NoiseReductionMode'] = 0
# huge frame duration range, to be free in exposure settings
config['controls']['FrameDurationLimits'] = (100, 32_000_000)
# finally, configure the camera
picam2.configure(config)
# check the configuration, if not log is available
# pprint(picam2.camera_configuration())
# start the camera
picam2.start()
# we want the lowest noise level possible
picam2.set_controls({'AnalogueGain':1.0})
# you need to set this appropriate for your setup
picam2.set_controls({'ExposureTime':5_000})
# get the camera time to settle
time.sleep(1.0)
for it in range(10):
# capturing a single frame with metadata
request = picam2.capture_request()
raw = request.make_buffer("raw")
metadata = request.get_metadata()
request.release()
# extract some info
exp = metadata['ExposureTime']
ag = metadata['AnalogueGain']
dg = metadata['DigitalGain']
# ... and print it out
print(f'Image: {it:02d} - exp:{exp:8d} ag:{ag:1.6f} {dg:1.6f}')
# create and save a .dng-file (should be handled in thread)
# picam2.helpers.save_dng(raw,metadata,picam2.camera_configuration()['raw'],'raw_%2d.dng'%it)
# stop the camera
picam2.stop()
The terminal output I when running this script reads like this:
rdh@raspi-06:~/cineRaw $ python captureRaw.py > info.txt
[0:37:54.828552974] [5480] INFO Camera camera_manager.cpp:316 libcamera v0.3.1+50-69a894c4
[0:37:54.861381279] [5485] WARN RPiSdn sdn.cpp:40 Using legacy SDN tuning - please consider moving SDN inside rpi.denoise
[0:37:54.864610794] [5485] INFO RPI vc4.cpp:447 Registered camera /base/soc/i2c0mux/i2c@1/imx477@1a to Unicam device /dev/media3 and ISP device /dev/media0
[0:37:54.864835382] [5485] INFO RPI pipeline_base.cpp:1125 Using configuration file '/usr/share/libcamera/pipeline/rpi/vc4/rpi_apps.yaml'
[0:37:54.878735275] [5480] INFO Camera camera.cpp:1191 configuring streams: (0) 4056x3040-RGB888 (1) 4056x3040-SBGGR12
[0:37:54.879232210] [5485] INFO RPI vc4.cpp:622 Sensor: /base/soc/i2c0mux/i2c@1/imx477@1a - Selected sensor format: 4056x3040-SBGGR12_1X12 - Selected unicam format: 4056x3040-BG12
rdh@raspi-06:~/cineRaw $ cat info.txt
Image: 00 83 msec | exp: 60.00 msec | ag:4.491228 1.509269
Image: 01 103 msec | exp: 66.46 msec | ag:5.988304 1.021969
Image: 02 97 msec | exp: 66.66 msec | ag:6.095238 1.001027
Image: 03 101 msec | exp: 66.66 msec | ag:6.095238 1.001027
Image: 04 62 msec | exp: 66.66 msec | ag:6.059172 1.003291
Image: 05 100 msec | exp: 66.66 msec | ag:6.059172 1.003476
Image: 06 403 msec | exp: 66.66 msec | ag:6.131737 1.002864
Image: 07 5017 msec | exp: 4999.94 msec | ag:1.000000 1.000011
Image: 08 5030 msec | exp: 4999.94 msec | ag:1.000000 1.000011
Image: 09 4961 msec | exp: 4999.94 msec | ag:1.000000 1.000011
rdh@raspi-06:~/cineRaw $
The last line of the libcamera-debug output (line 7 above) states “Selected sensor format: 4056x3040-SBGGR12_1X12” - this is the sensor format we want to have. Always check that you get what you have requested.
Note that the actual program output shows (your results might differ) that it takes libcamera a total of 6 frames to deliver actually the exposure we requested (5000 ms). Until than, libcamera/picamera2 simulates your requested exposure time with a large AnalogGain value - which leads to increased noise levels.
Speaking of gains: the only gain relevant with respect to RAW data is the AnalogGain, as this is applied in-sensor. The 'DigitalGain` is applied afterwards, when computing an LDR (.jpg or .png) and irrelevant with respect to RAW data.
Let’s go through some of the more important lines of the script.
if True:
# load alternative tuning file
tuning = Picamera2.load_tuning_file('imx477_scientific.json')
picam2 = Picamera2(tuning=tuning)
else:
# start with standard tuning file
picam2 = Picamera2()
loads the tuning file we want. Set True to False if you want to compare the standard tuning file to the scientific one. Emphazing this again: do not use the standard one for telecine work. The standard tuning file has some funny settings. For example, it includes lens-shading information for an unknown lens. If you use for example an enlarger lens for your scanner, you certainly do not want to use that lens-shading data.
For example, the Schneider 50 mm is calculated for a much larger format (35 mm), there is no need to apply any lens shading correction - the tiny center section the HQ sensor is using does not show any lens shading effect. Accordingly, the “imx477_scientific.json” has no lens-shading section at all.
Continueing with the above script. To set up the sensor, we start with one of the standard configurations offered by the picamera2 lib:
# create a config with defaults
config = picam2.create_still_configuration()
Proceeding this way, we only need to change what is important. Less work.
First, we increase the buffer count. Any still_configuration works with a single buffer as default. This would slow your program down. Requesting more buffers is quite a memory intensive operation, so we are somewhat limited here. On a standard RP4, you can not allocate more than 4 buffers; on an RP5, one can work with 6 buffers easily (this is the standard of a video_configuration.
# increase buffer count (RP4 -> 4 buffers/RP 5 -> 6 buffers)
config['buffer_count'] = 4
The next important line is the following:
# full frame, uncompressed raw -> max. 10 fps
config['raw'] = {"size":(4056, 3040),"format":"SRGGB12"}
This actually gives us the full format 4k uncompressed raw stream we are after.
Skipping a few unimportant lines, the whole config is finally applied to the sensor by the line
# finally, configure the camera
picam2.configure(config)
The rest of the code is probably rather self-explanatory.
If you run the script as given above, no .dng-files will be written to your SD card. If you want to write out the .dng-files, you have to uncomment the appropriate line like this:
# create and save a .dng-file (should be handled in thread)
picam2.helpers.save_dng(raw,metadata,picam2.camera_configuration()['raw'],'raw_%2d.dng'%it)
If you do so, you should end up with 10 .dng-files. Be sure to adapt at least the exposure time to your needs, chances are that otherwise you only get black images.
For storing the captured .dng-files, I use two different ways. One way is to attach a fast SSD via USB3 to the RP5 and use something similar to the above code.
Usually however, I simply stream the .dng-files directly from memory via LAN to a larger Win-PC. Here’s a code snipet achieving this. “self” is here simply a Picamera2 object, with the added function
def saveRaw(self,scanCount):
stream = io.BytesIO()
self.helpers.save_dng(self.raw,self.metadata,self.camera_configuration()["raw"],stream)
size = stream.tell()
stream.seek(0)
data = stream.read()
packet = [8,size,scanCount,data]
self.dataStream.put(packet)
del stream,size,packet
Like in the above script, this function uses the RAW data, as well as the saved metadata and camera_configuration. However, the dng is created into memory, in the variable stream which is of the io.BytesIO type. Note that this is only possible with the most recent picamera2 lib versions.
The .dng-data created, “data”, is packed together with some other stuff (“8” indicates for the receiving software that it is a raw data frame, “size” gives the length of the whole data packet and “scanCount” is simply the current frame number) and finally send to the Win-PC, by putting it into a send queue: self.dataStream.put(packet). The queue itself is transmitted in a separate thread towards the Win-PC.
This dng-save function is triggered in the main capture loop like so:
threading.Thread(target=camera.saveRaw,args=(camera.LDRcount,)).start()
In that way, converting to .dng and transmitting that data to the larger workstation does not waste any capture time. By the way, “camera” in the above program line is the Picamera2 object mentioned previously.
The raws captured in this way amount to approximately 23.4 MB of disk space for each frame on a Win-PC. That is about 85 GB for a single 15 m roll of S8 footage @ 4k. Not too bad. You can load these files directly into DaVinci Resolve. How to do this further processing is left for another day…