I liked following the Sasquatch 70mm build thread so much, I thought it would be fun to also chronical my progress from (nearly) the beginning.
My name is Nicholas and I’ve been planning to build one of these things for almost a decade. I figured it was time to stop planning and start building, so my goal now is to complete some measurable chunk of work each month in 2023 (starting in Feb) to hopefully have a machine that does something by the end of the year (and write about it here as I go along).
The Starting Point
- About fifty 3" reels of 8mm and S8 Kodachrome family movies shot between 1954 and 1985.
- A Lucid Triton 2.8MP GigE camera: IMX429, 2/3", monochrome, 1936x1464, global shutter.
- The usual Schneider Componon-S f2.8/50mm lens.
I like monochrome because it might give better control over colors and it could maybe squeeze more resolution/fewer artifacts out of an otherwise same-resolution sensor with a Bayer filter.
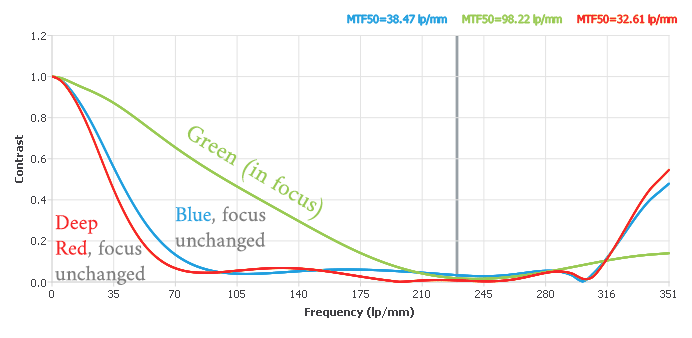
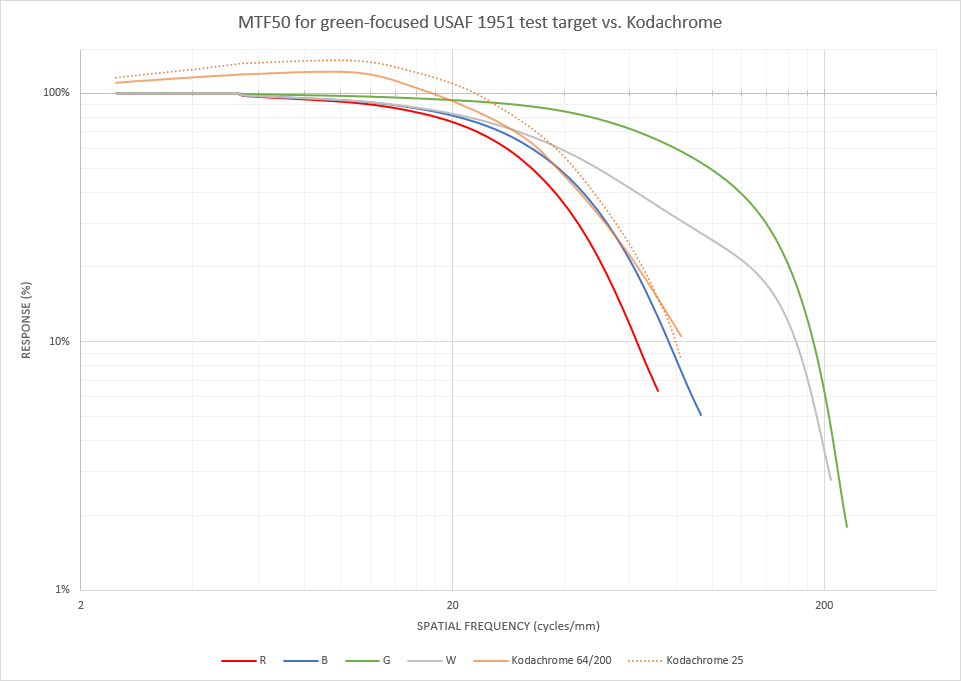
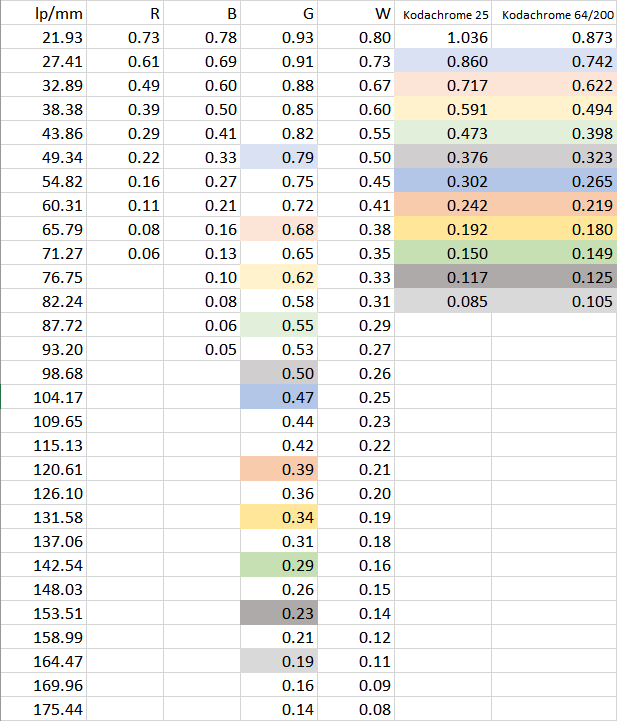
At 2/3", I’ll be running at 1.35x’ish magnification for 8mm film, which is a little higher than most of you RPi HQ folks. But, the extra 1um of resolution in CoinImaging’s “resolving power vs. magnification” chart (vs. 1.0x) that matches this sensor’s pixel size almost exactly made it feel worth it. The nice, deep wells on the Pregius gen3 sensors also felt like a good answer to keep the number of HDR/fusion exposures low. I’ll be curious to actually measure the dynamic range I can get out of this thing.
Areas of Interest
To answer “which features am I hoping will make the ReelSlow8 different?”, I’ve got a few experiments I’d like to try in the coming months:
-
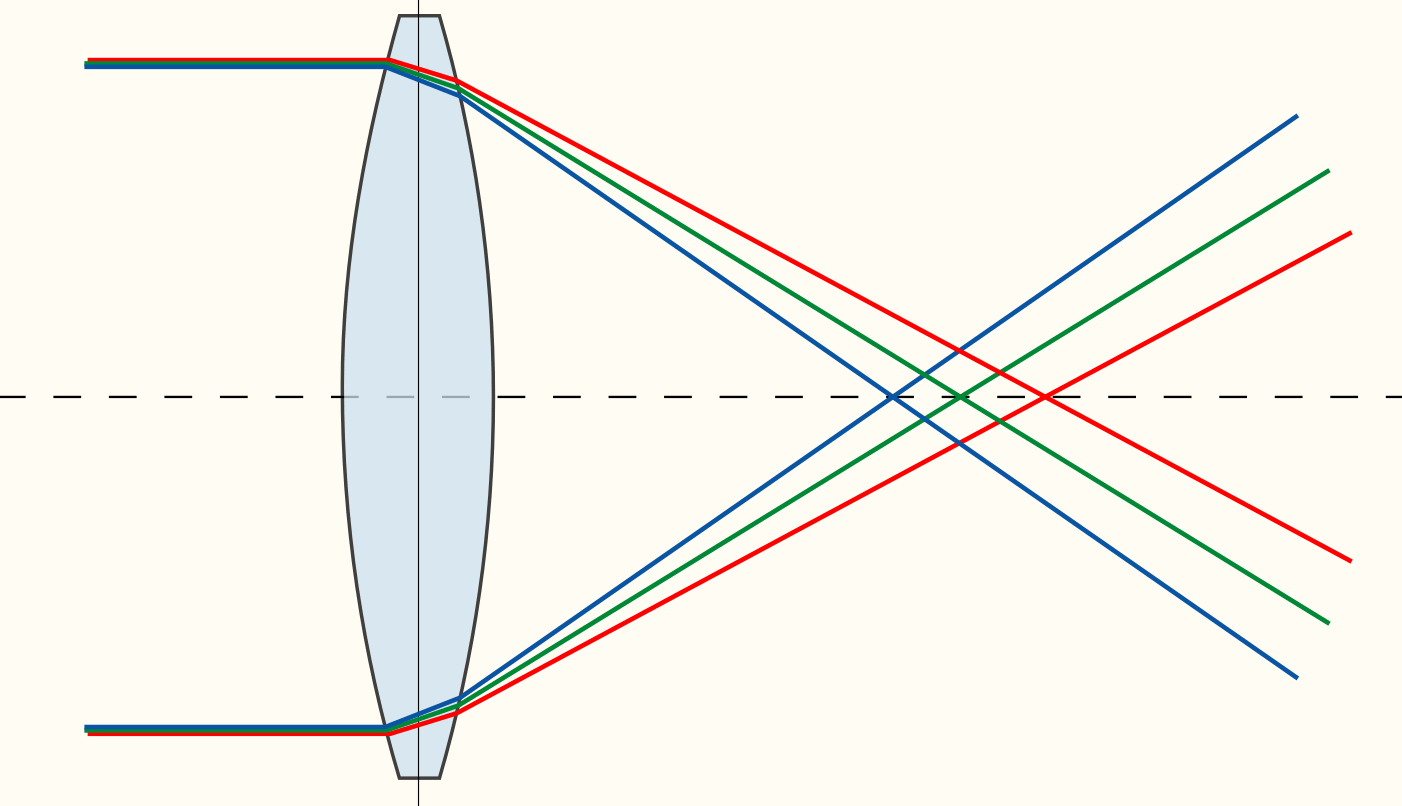
An overkill auto-focus system. I absolutely do not trust myself to dial in any part of this machine. I have this way-oversized (280mm) ball-screw linear stage that I’ll be mounting the camera on, controlled with a stepper. But even more than that, I want the image plane to be fully adjustable and under the control of software: one corner fixed and two others that are motorized so the software can get a more exactly parallel image plane than my hands on an adjustment micrometer. For the main camera focus axis, I want to be able to chase microns. I had a bad experience with a different lens that had lots of axial CA so I want this thing to be able to focus on each emulsion color layer individually, if need be.
-
A tiny 8mm wet gate. After poring over lists of strange chemicals (and their refractive indices) and having chemical supply companies turn me down for years, I finally found someone that would sell isobutylbenzene to a residential address! (The answer in the US is Chemsavers.com, but lab-grade reagents are ridiculously expensive. It’s frustrating when the one liter you can actually get someone to ship to your house costs more than the 50gal drum you’ll never be able to buy from Aliexpress… but that’s the world we live in, as far as I can tell.)
For the curious: on all of Kodak’s literature about IBB, I’ve seen things like “persistent odor” mentioned a number of times, but never any description of the smell itself. I can now make a first-hand report: it’s a little like black licorice, but worse.

-
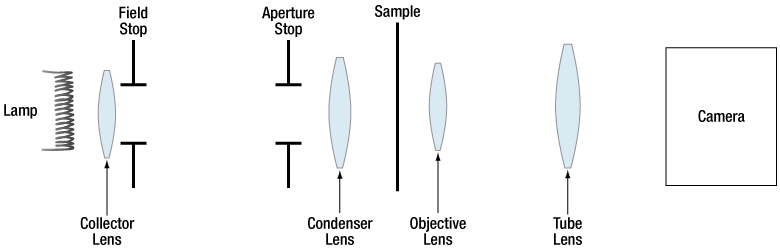
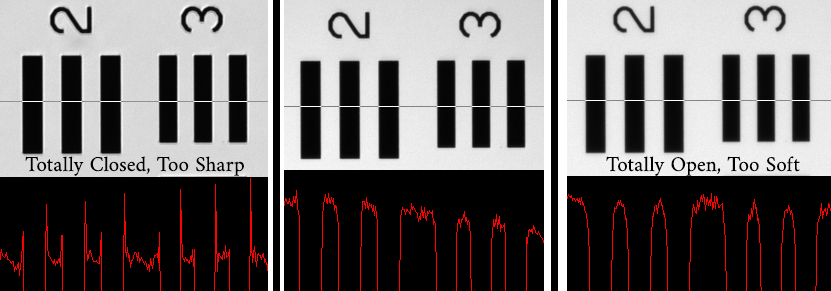
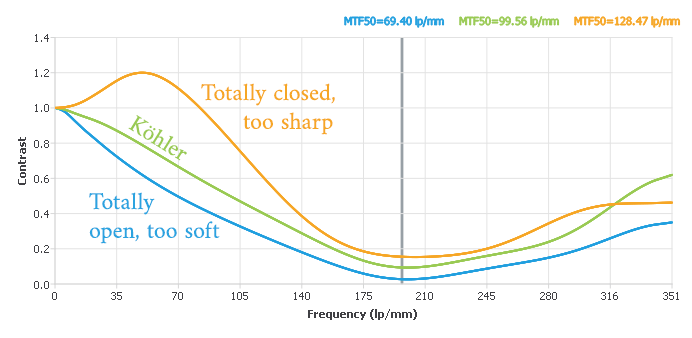
Collimated condenser/Köhler lighting (vs. integrating sphere/diffuse). If I’m going to the trouble of a wet gate with the right index of refraction, I’d like to keep as much of the contrast ratio intact as possible.
-
IR or dark-field cleaning. Kodachrome is partially opaque to IR, so I’d like to tinker with dark-field imaging to maybe grab a dirt/scratch channel. This is a lower priority because I have high hopes resting on good pre-scan cleaning hygiene and the wet gate doing most of the heavy lifting here.
-
Lots of post-processing. The VideoFred scripts are an inspiration to me. Temporal inpainting and motion interpolation are very exciting. And–more recently–adding “AI” onto the front of either of those terms yields search results that look a little like magic. My target is something as good or better than the “Thanksgiving dinner” video at the bottom of this page.
-
The distribution of these films to my family is just as important as the scanning. They’ve actually already been digitized once by a couple of my uncles, back in 2011. The best they had available at the time was a DV camcorder pointed into a projector + mirror box. The resulting 480i60 / 4:1:1 recording often had half the fields blown out by over-exposure when the scene brightness would change, frequent focus hunting, and the projector’s small, square gate hid about 30% of the image.

But more than the possible improvement in image quality, trying to find the clip you wanted was the trickier part. The end result was a pair of DVDs with about 4 hours of footage in the order they pulled the reels from the old box. Unless you were planning to sit and watch all the way through, the only way to see the thing you wanted was lots of seeking and maybe a disc swap. For some of the “kids” (now in their 40’s and 50’s) that were featured, they might have to skim the whole collection to find the only 5 minute clip they were in.
My plan is to make a simple, private website with a chronological timeline cataloguing each scene, a family tree at the top that can be clicked to filter for a particular person, and a list of categories (Christmas, vacations, weddings, etc.) to further filter the list. Ideally I’ll have enough metadata that someone could find the clip they’re looking for in only a few seconds and optionally save a copy to their phone/tablet in one more click.
It’s a small detail, but if an old family film is scanned in the middle of a forest and no one is there to watch it, does it really exist? I try to keep in mind that the accessibility of these memories is just as important as their image quality.
February: Light Source
Let’s kick this thing off with some real work that I did over the last few weeks!
I’ve had some wacky ideas for light sources in the past. (See my profile pic for one bad idea.) I’d settled on a linear (non-PWM) multi-channel source and got some great tips a few years ago on a circuit design that only used a single LM317 to drive several different current levels.
I didn’t have variable current control high on my list of priorities but have since read here that these sensors can be much slower at changing their exposure settings. This sensor has a global shutter, so as a last resort I suppose I can use a timed pulse scheme if the camera ends up being uncooperative.
Because this isn’t a continuously running system, I don’t need to freeze the motion, so I can get away with a lot less light. That means having the convenience of low voltage and low current. This design tops out at about 2.5W (10V at 250mA), which fits neatly inside the spec for the 28AWG wires in a mini-DIN cable. So I was able to use a convenient single power+signal connector.
This uses a combination of Cree, Luminius, and Yuji LEDs. There’s a bit of kitchen-sink thrown in here with White, RGB, and IR channels. Because my project is predominantly exploratory/experimental, I didn’t know what I was going to need, so I included everything, hehe. The RGB wavelengths are 450, 525, and 660nm, which match the optimal wavelengths for decorrelating the color channels (as best as I could tell) from the chart in the Diastor paper. The IR channel uses 940nm. I’ve tried the (much more expensive!) 1050nm range in the past and didn’t find any difference with Kodachrome besides less sensor sensitivity; so sticking with the mid-900nm range was easiest.
The voltage drops on each LED were close enough that I was able to get two in series for each channel except red (with three), while running on anything over 10V. I’ve been trying to teach myself electronics over the last two years, so I also used this particular board to practice input and power safety design (hence the TVS, MOV, fuse, choke, and input protection which is almost all certainly overkill when it’s going to be run from a clean bench power supply).
Here’s the circuit:
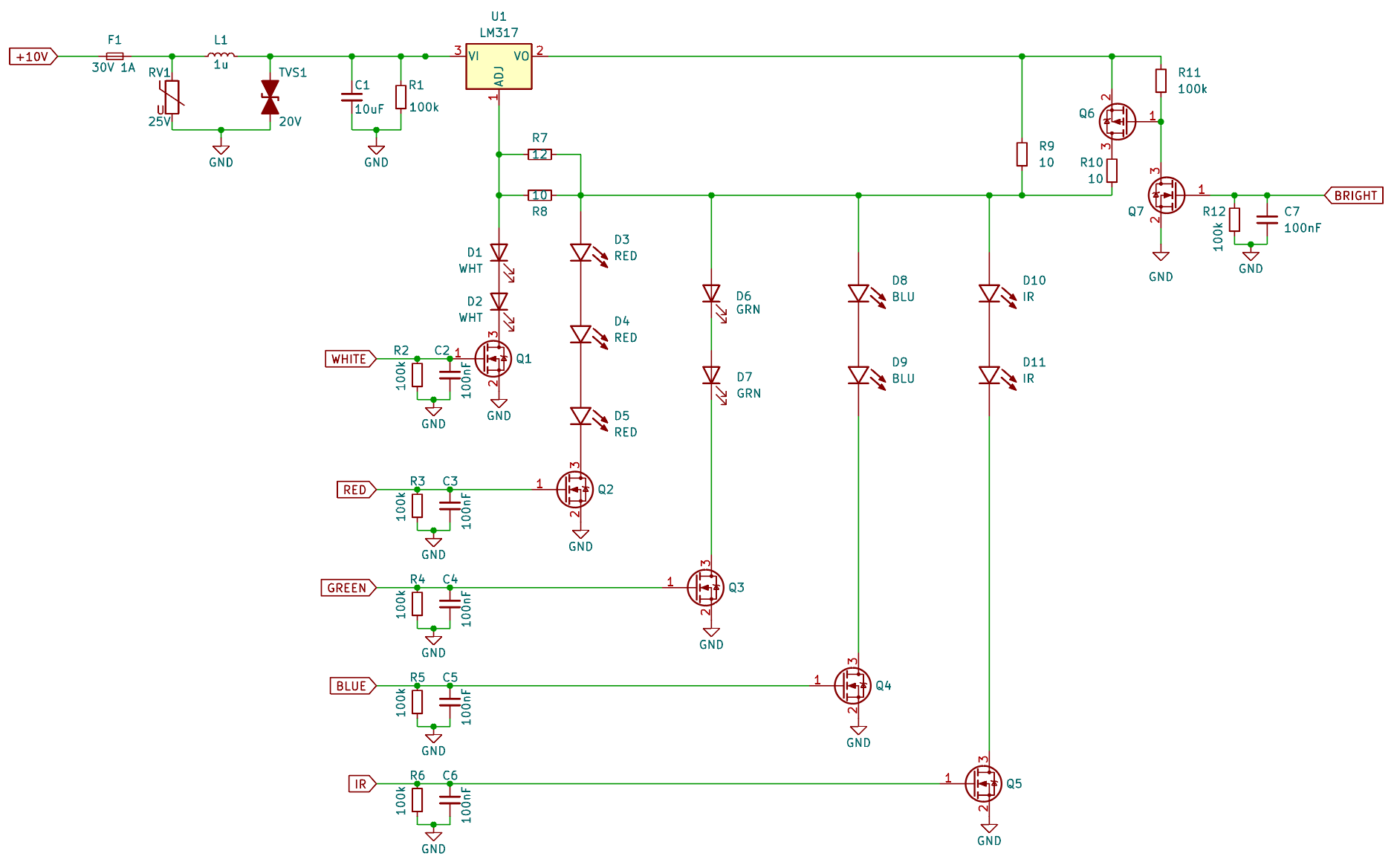
It uses the idea from that StackExchange link above where the LM317 will deliver a few different distinct current levels. The white Yuji LED needs a fairly precise 120mA to be inside its CRI spec. But the single-wavelength LEDs can go all the way up to 350mA. I decided to keep them around 250mA to be conservative. Then, because I had an extra pin left on my connector, I wondered if it might be handy to be able to toggle between two current level presets for the sake of controlling exposure times. It’s not quite like having a fine control knob, but it was only an extra high-side PMOS switch and now the individual channels can be toggled between 130mA and 250mA just by setting the “Bright” pin low/high.
The challenging part of the layout was getting all the LEDs to fit in a tiny square. My aspheric condenser lenses are 50mm, and I wanted the lights to fit well inside that circle. And even though they’re going to be well-diffused on the light input side, I still wanted the color channels to be radially symmetric around their center, which led to a lot of fun criss-crossy routing on my plain two-layer board. (This was exacerbated by my insisting that all the LEDs be oriented the same way for ease of hand-populating the board with tweezers. Changing their orientation would have made the routing easier, but I know I would have made a mistake and installed at least one backwards.)

The M3 hole pattern at the top is only 16x23mm. Nice and tiny!
The inputs are tolerant of anything from around 2.5V up to 12V. I remembered I had a little Cherry MX key-switch tester and some solid-colored keycaps (from a different project) that coincidentally matched these colors. So I soldered a few wires directly to the key-switches to make a fun little test harness.

I have the light output turned way down for the sake of recording this demo video. Even just at 120mA and 250mA they’re painfully bright to be around normally. (The gray button I don’t press in the video is for IR. The one on the end is an old Cherry MX Lock switch that physically toggles on/off when you press it. That’s the “bright” signal.)
Eventually all of this will be connected to a microcontroller of some sort, but these clacky keys will work for testing in the meantime.
What’s Next
I’ve got a few immediate tasks before I can get started on anything more substantial. I’m planning to use MakerBeam’s 10x10mm and 15x15mm aluminum extrusions to hold everything together. Until it’s time to do wet-gate things, this is going to be a horizontal, tabletop build. So I need to get this mess connected to a rail system so I can start orienting things like imaging planes, the light PCB, and the condenser lenses:

So far this is an example of how not to build a stable platform. Most of the 3D printed parts will eventually be replaced by milled/lathed aluminum. The stacked XY and rotation tables will be moving to the light source (so I can properly center things per Köhler illumination) and I’d like to get the sensor+lens a little lower and closer to its center of mass instead of flapping in the breeze the way it is now. (The only adapters I could find for reverse-mounting the lens involved a Canon EF-mount, which makes the whole chain pretty hideous and a lot heavier than it needs to be. The step-down converters on the front are just there to protect the exposed rear lens element for now.)
After that I need to dust off some microcontrollers and convince myself I remember how to drive a stepper motor. Hopefully I’ll be able to tackle all of that in March.
Whew. That was a lot of typing. ![]()
I am excited to finally start participating here and adding what little I’m able to discover to the great pile of accreted knowledge on this board. Please let me know if any of the above was confusing or if anyone has any questions!