May: Pixel Size, Focus Detection, and Planarity
I didn’t get quite as far as I’d planned on full-fledged auto-focus, but the digression into measuring the size of each pixel was worth it.
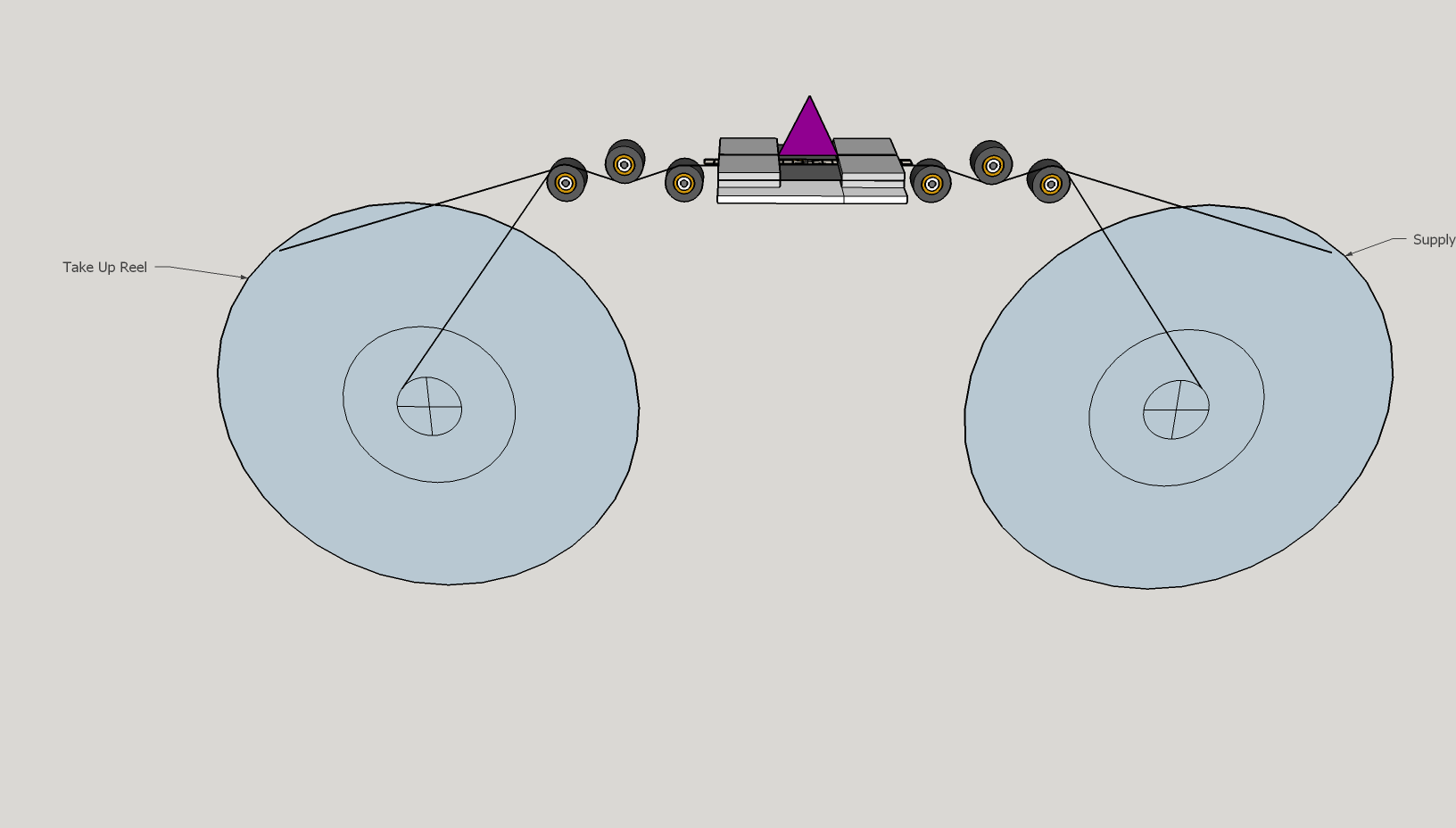
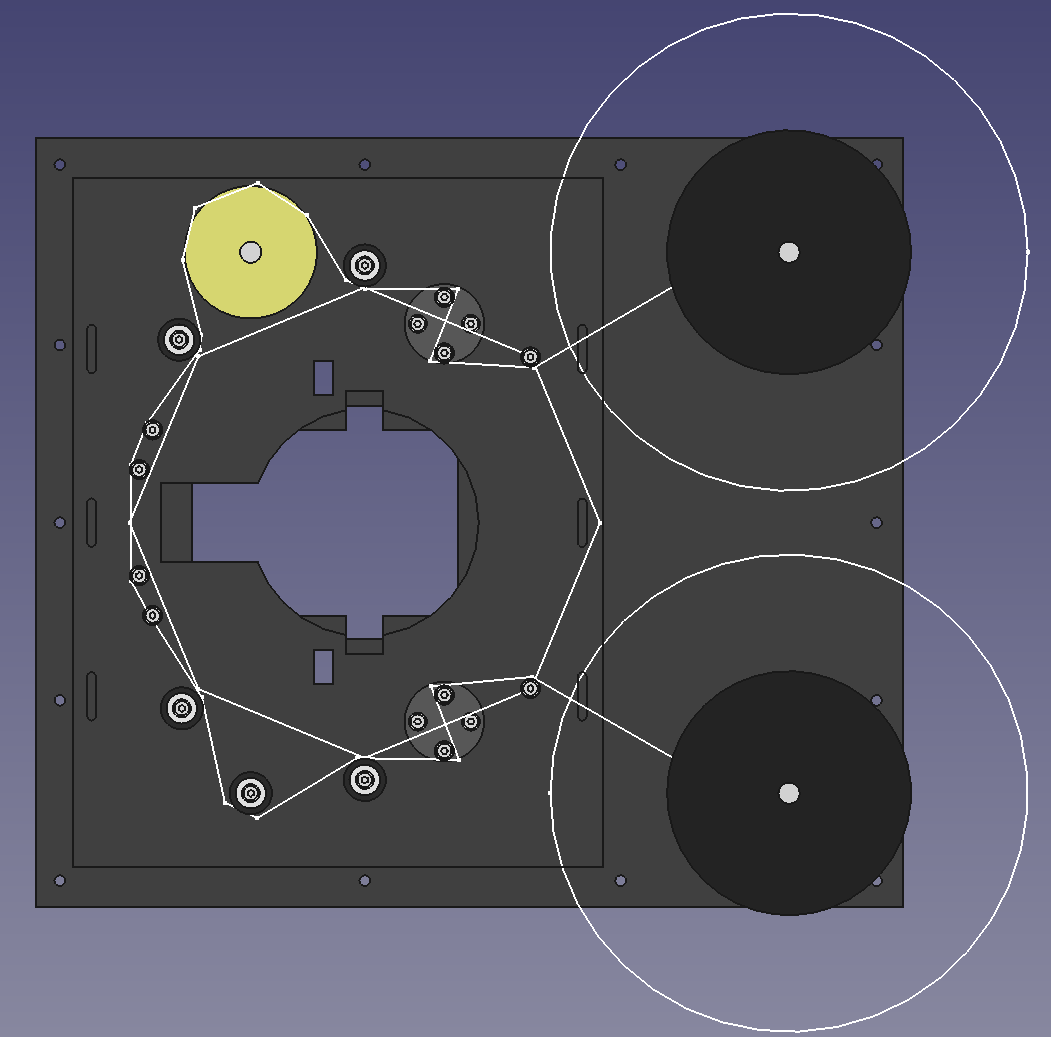
The machine is starting to look like something:
The software is still mostly debug buttons and other manual testing/control bits, but the number of things it can do is steadily increasing:
In particular, I’m happy with my decision to use Dear ImGui for the UI. I’d never used it before, but on average it takes a single line of code to both add a new button and the code for what that button does (no extra callbacks, etc.), so the framework stays completely out of your way and lets you get your work done.
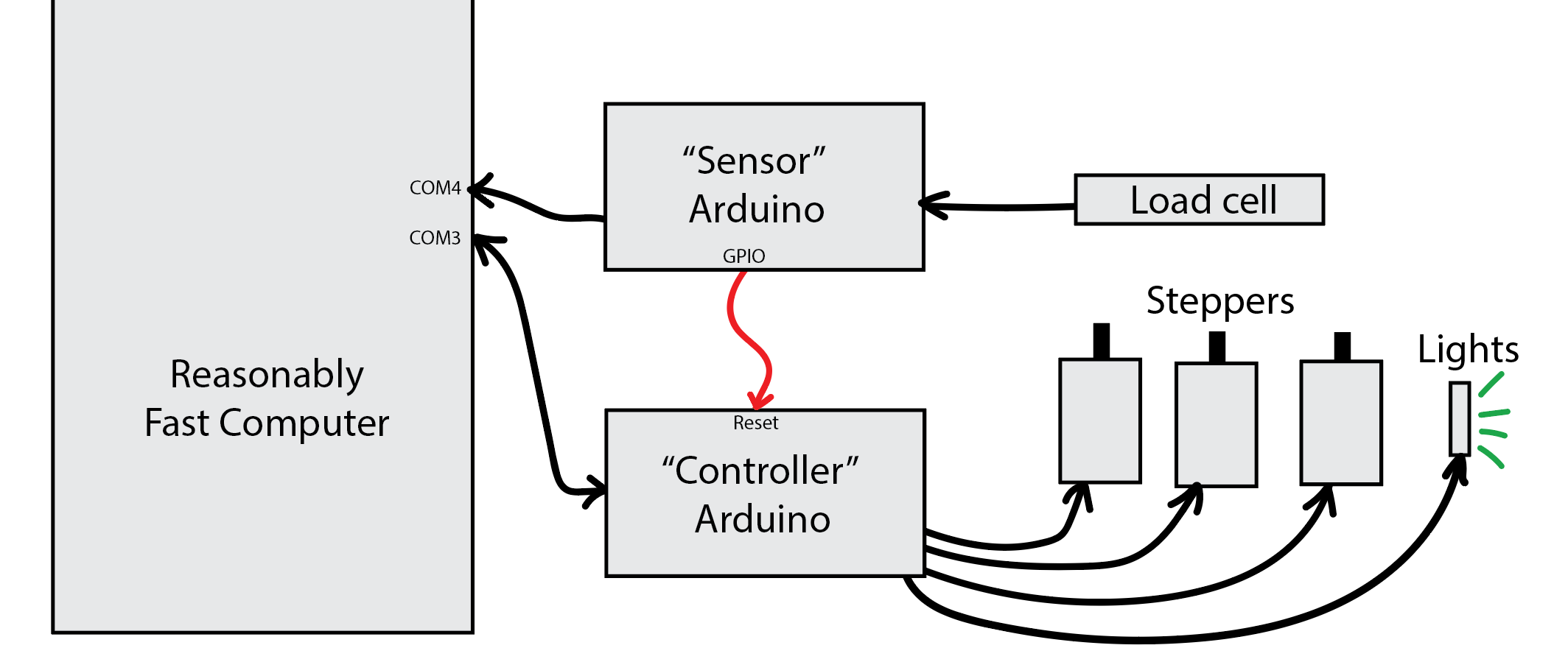
The communication between the Arduino and the Windows app is going smoothly. I came up with a little protocol where each message (and reply) is between 1 and 5 bytes for all of these primitive operations like changing the light color, delaying for some number of microseconds, or taking some number of linear motor steps. But then there is a mode where you can say “start accumulating instructions until I tell you to execute them all at once”. That takes USB jitter, parsing overhead, and most other sources of latency out of the equation. So it should be able to do things like strobe the lights with repeatable timing when triggering the camera’s GPIO pin to acquire an image, if need be.
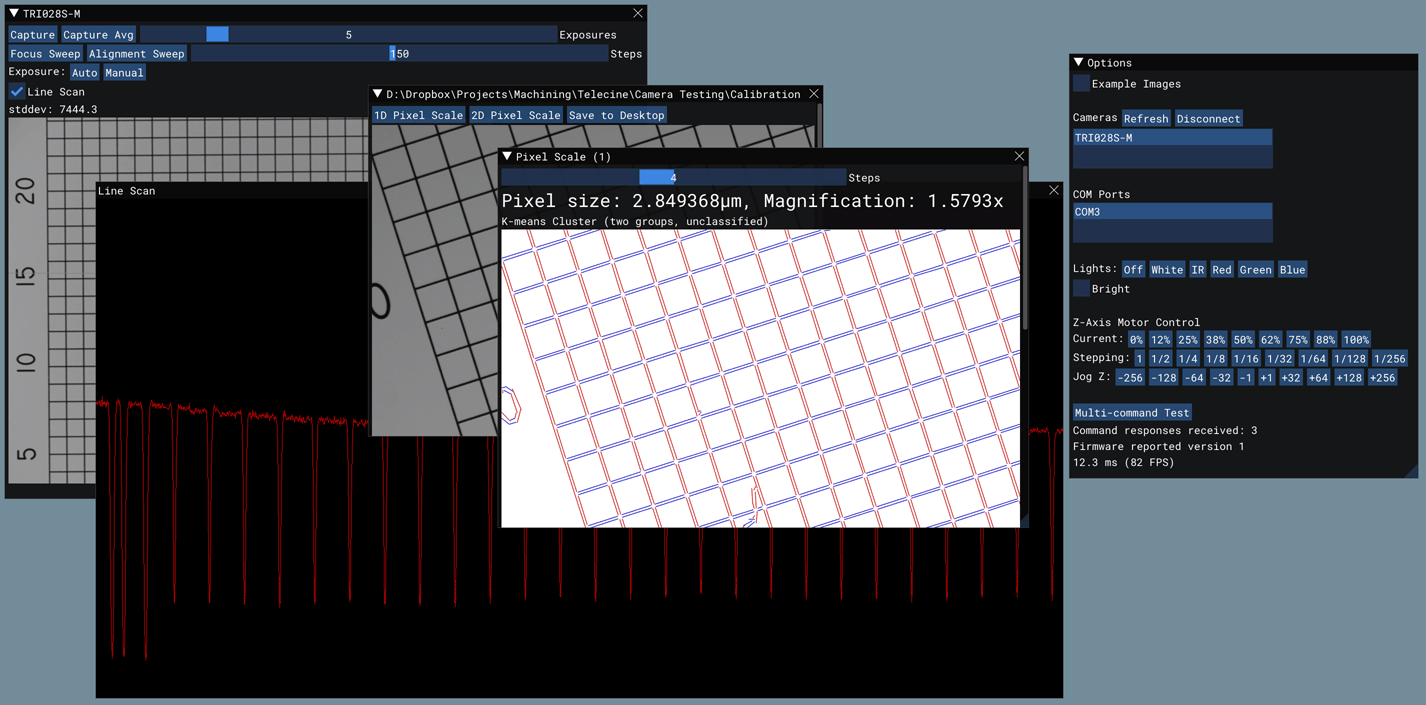
Measuring Pixel Size
Last time I said my biggest fear was going to be a large change in the size of pixels between the best focus point for each color channel. I’ve since been able to confirm that the size of the pixels does change but not so much that it isn’t something I won’t be able to correct for in software with some very gentle resampling.
The first step was being able to reliably hold these calibration targets. I was having trouble getting something held in place tightly while still being able to make fine adjustments, so I cobbled together this little slide holder that uses springs to hold the slide against a fixed surface.
Those are toothpicks holding the springs under tension. I switched to a full grid calibration slide that is a small, round disc with a target that’s roughly the size of an S8 frame, which is perfect. So that’s what’s sandwiched between the plastic layers there in the photo.
Until now, I was measuring pixel size manually by capturing an image, using the ruler tool in Photoshop (which snaps to whole pixels), and doing the math by hand. But I wanted sub-pixel accuracy and more measurements to average across to make the result more precise.
After some tinkering with OpenCV, I came up with something pretty cool for the single-axis (1D) target. It was a little brittle and required a nice, sharp capture without any dirt in the frame, but I was getting some reasonably good numbers out of it. But then two days later I figured out how the idea could be extended gracefully to the full 2D grid target in a way that was much less finicky about the quality of the image.
Here are the broad strokes of the algorithm being run on an intentionally skewed and dirty frame to show its resilience:
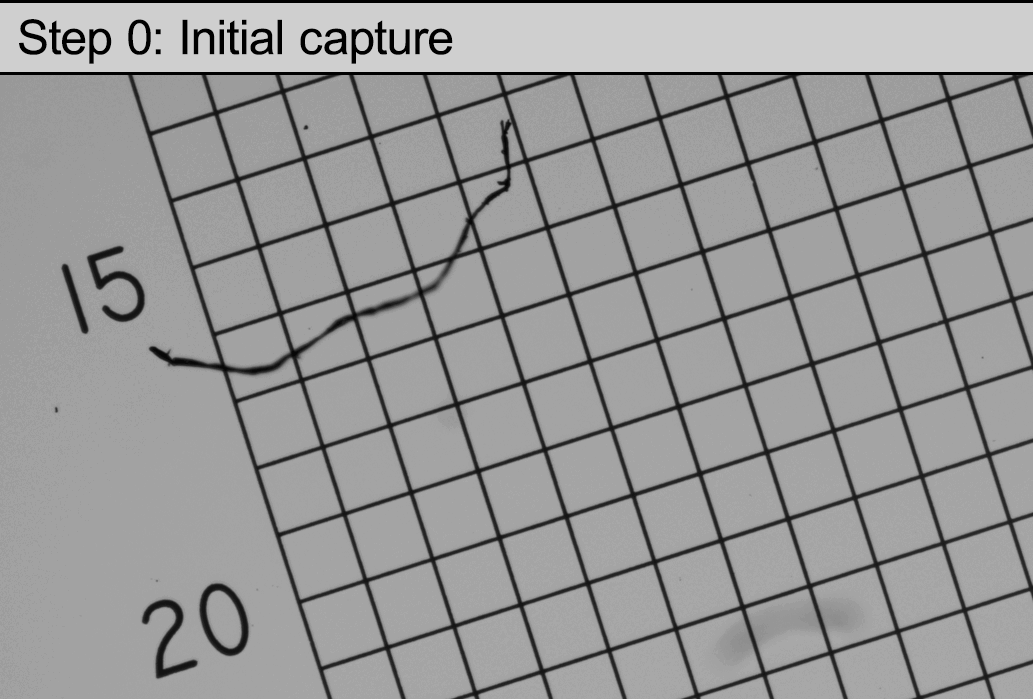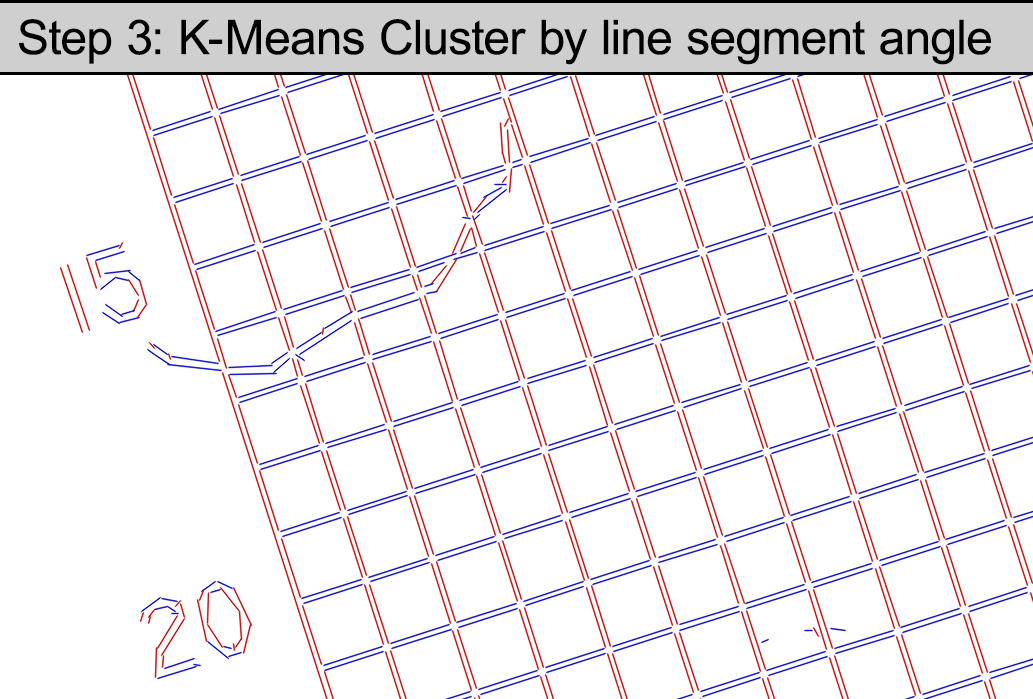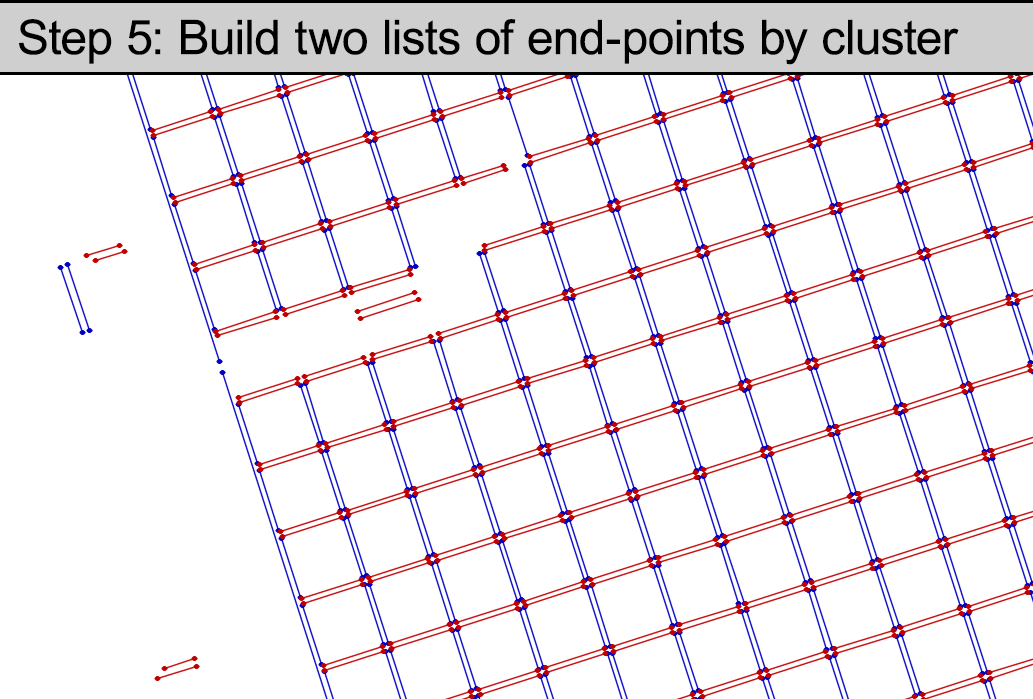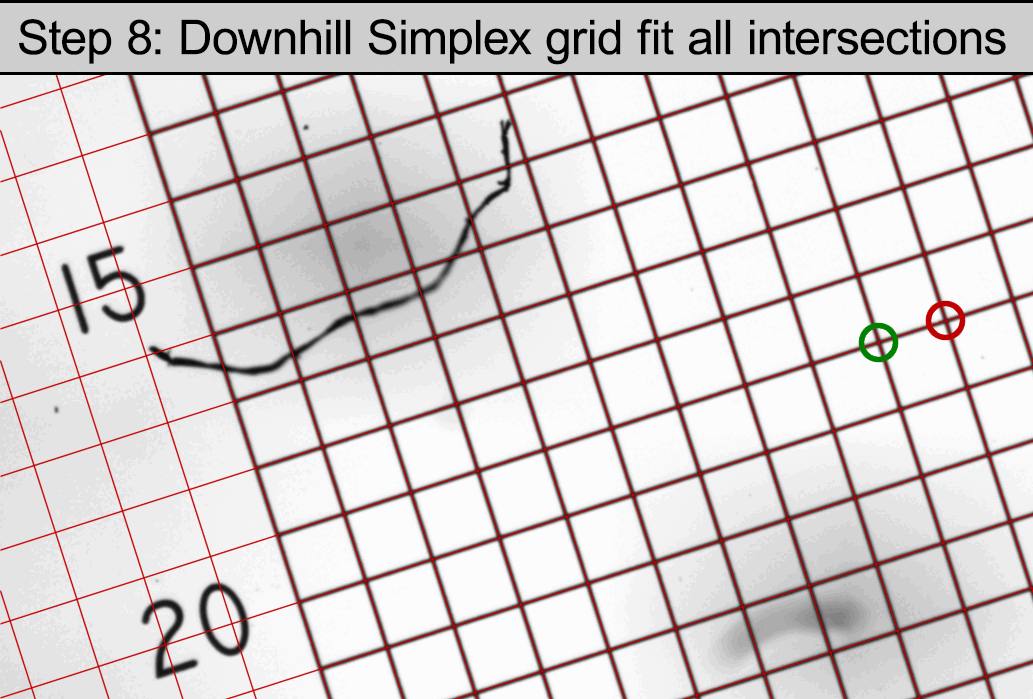
(Be sure to click the “Play” button on the animated GIF. The forum software seems to prevent it from animating automatically.)
Step 1 is running the CLAHE algorithm built into OpenCV to bump the local contrast up for line detection. There is some gentle blurring being done here too, which I didn’t show in the animation.
Step 2 is picking out line segments using OpenCV’s cv::createLineSegmentDetector. (Specifically this does not(!) use the Hough transform line detection; I spent a lot of time there and was getting poor results, whereas the LineSegmentDetector feature worked beautifully on the first try after I found it.)
Step 3 is where it starts to get cool. Find the angle of each detected line segment (wrapping it into a half-circle so that a 1 degree angle and 359 degree angle show up as 2 degrees apart instead of 358), and then run K-Means Clustering (with two groups) on it. OpenCV also has this feature built-in with a nice, easy API for using it. What you’re left with is two lists of line segments that are grouped by what you might call “horizontal” and “vertical”, except there is no dependency on the grid being aligned with the camera sensor.
Step 4 is now that we have the cluster centroids, which are a kind of “ideal” angle, we can check that they should be almost exactly 90 degrees different from each other, and throw away any line segments that aren’t close. This cleans up almost all of the noise, dirt, and other elements from the image.
Step 5 breaks each list of line segments into two lists of points containing the end points of each line segment. So, both endpoints from each “horizontal” line go into one big list and both endpoints for each “vertical” line go in a separate list. At this point we are done with the lines and they can be discarded. The endpoints are the blue and red dots in the animation.
Step 6 finds pairs of endpoints–one from each list–that are closest to one another. There is no special ordering required: pick any point from the first list, go through the second while making note of the closest match. Find the midpoint between those two and insert it into a new “corners” list. Throw away those two points and repeat until one of your point lists is empty. Now we’re done with the endpoints and they can be discarded. The corners are the green dots in the animation.
Step 7 finds groups of four corners that are all close to one another within some tolerance. Pick any corner at random, sort the rest of the list by how far each corner is from that one, grab the top three. If any of them is much farther than the others, the corner we started with doesn’t belong to one of the intersections in the calibration target, so it is thrown away. Otherwise, find the midpoint between all four and insert it into a list of “intersections”. Now we can throw those four corners away and repeat until the list of corners contains fewer than four entries. At this point we’re done with the corner list and it can be discarded. The intersections are the green circles in the animation.
Step 8 is kind of magical. I knew about gradient descent, but I don’t have an easy way to calculate the derivatives necessary in this situation. While digging around for numerical methods of fitting data, I saw a mention of the downhill simplex method, which I’d never heard of. It does something similar to gradient descent but only requires the original function and not the partial derivatives. Even better, I found this lovely, single .h file C++ implementation of the algorithm.
The idea is that you give the algorithm a function and a set of starting parameters that can be passed to that function. It perturbs the parameters (in a very specific way), exploring the problem space, checking each result against the function until it finds the minimum value.
In this case, I just pick the intersection we found that was closest to the center of the image and then the intersection next closest to that one. (Pythagoras tells us we’ll always get an adjacent point and not a diagonal, no matter the rotation angle of the grid.)
The parameters to the downhill simplex algorithm are simply the (x, y) coordinates of those two points. The line segment formed by those two points is actually enough to define an entire grid: the line segment’s length is the grid spacing and the line segment’s angle defines how the grid is laid out in the plane. So all that is left is to provide downhill simplex with a function that tests all of the other intersections we found, snapping them to the nearest point on some hypothetical grid, and reporting the error between them. Downhill simplex minimizes that error and finds the ideal grid that fits each intersection most closely. It returns two, sub-pixel (x, y) pairs that are ever so slightly different than the initial parameters, that now fit all ~650 intersections best instead of just those two.
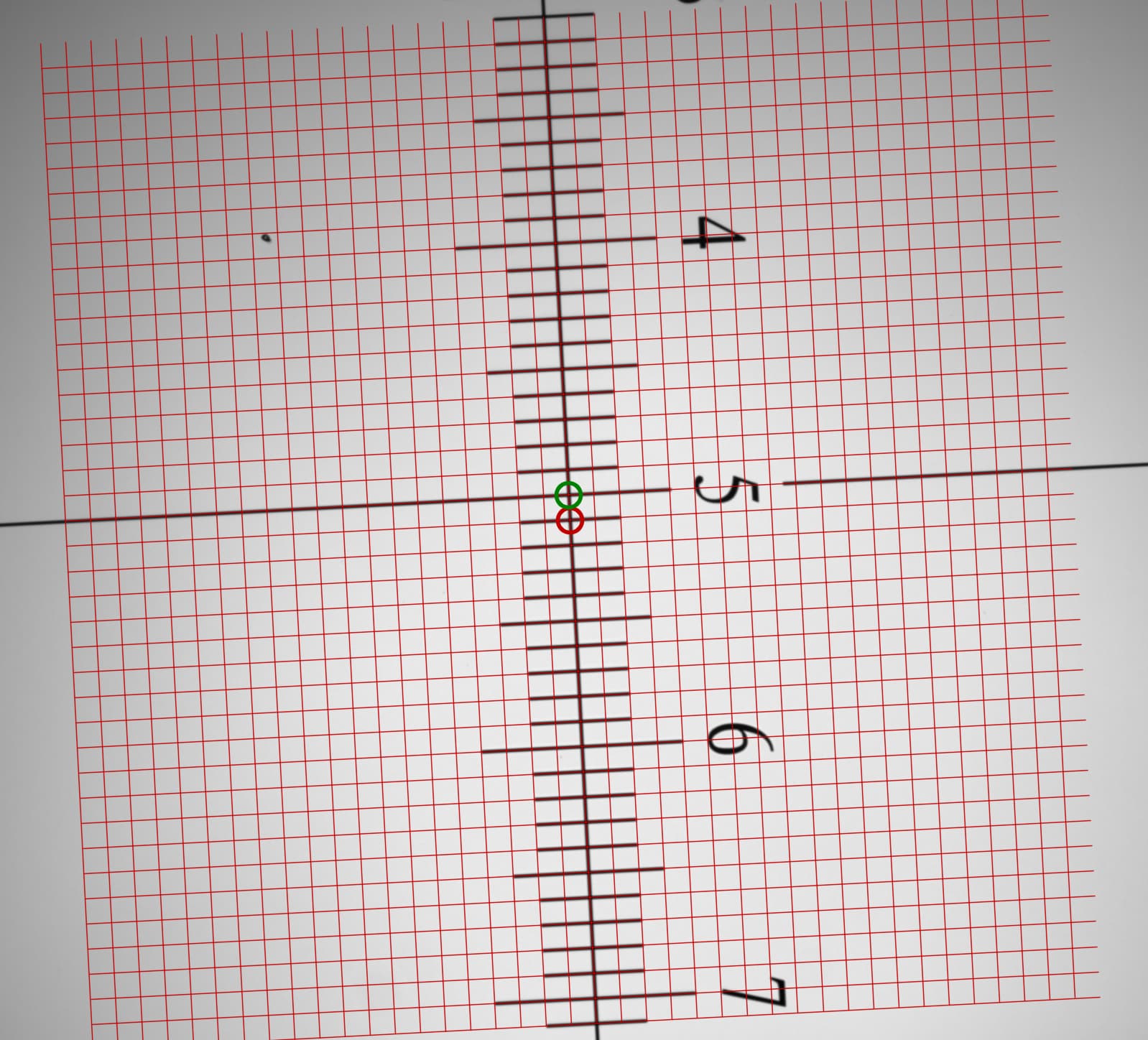
The red grid overlaid on top of the original image in the final frame demonstrates several things:
- Downhill simplex is easy to use and gives good results.
- The Schneider Componon-S 50mm f/2.8 lens has a remarkably flat field of view with essentially zero distortion, even at the corners.
- Even with all the junk in the line detection step, this algorithm is very resilient to missing or noisy data.
The earlier 1D version of the algorithm used the same steps 1 through 7 but had an extra three or four steps after to categorize things, find the scale’s axis, throw away intersections off the axis, order them, and check for consistent spacing between them. It was more brittle and couldn’t handle a single mis-detected point on the calibration slide (because of dirt, etc.).
So, one funny consequence was that the 2D algorithm continued to work in the 1D case and was more forgiving of bad data to boot. (None of those steps required the existence of a 2D grid; we only need evenly-spaced intersections.)
The size of each pixel can be read off directly: the length of the line segment is already given in pixels, and we know the length of the division in physical units a priori from the Amazon listing. 
Here are some results for my particular IMX429 sensor and extension tube setup. These are the size of each pixel at the best focus position for each color channel:
- 2.8557 µm/pixel for red.
- 2.8552 µm/pixel for blue.
- 2.8503 µm/pixel for green.
- 2.8522 µm/pixel for white.
- 2.8798 µm/pixel for IR.
Something jumps out right away: red and blue have nearly identical pixel sizes! Keep that in mind for later. 
Knowing that the sensor has 1936 pixels across, you can do the math and figure out that a picture of some object that is 6mm wide will end up ~3.4 pixels wider when taken with green light than it will with blue or red light. (For IR it’s almost 20 pixels narrower!) Assuming they’re aligned by the image center, by the time you get out to the edges, green will be off by almost two pixels. (For higher resolution sensors like the RPi HQ camera, this will be about 2x worse because it has about 2x as many pixels across.)
Instead of trying to correct for the effect by adjusting a bellows for each color channel, I think I’ll just resample each channel in software down by (up to) four pixels, realign them, and call it a day. That should clean up any color smearing at the edges and in the corners.
Focus Detection
The simplest metric for detecting an image’s relative focus is just taking the standard deviation of each pixel value in the image. That’s a one-liner in OpenCV, so it’s what I started with.
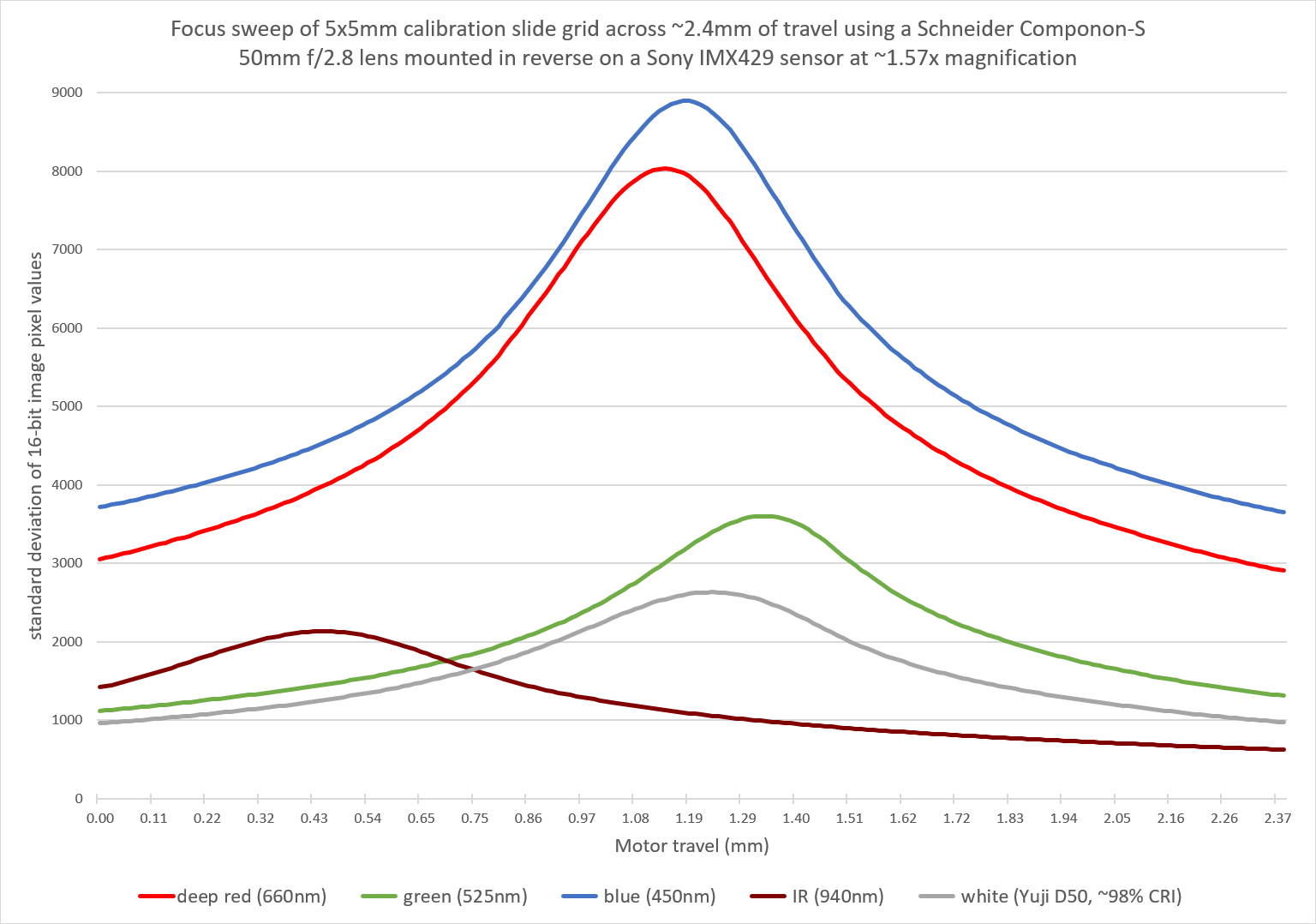
So we can see where our best focal planes are by walking the camera’s Z-axis forward one step, capturing an image using each color channel, and calculating the standard deviation of each image.
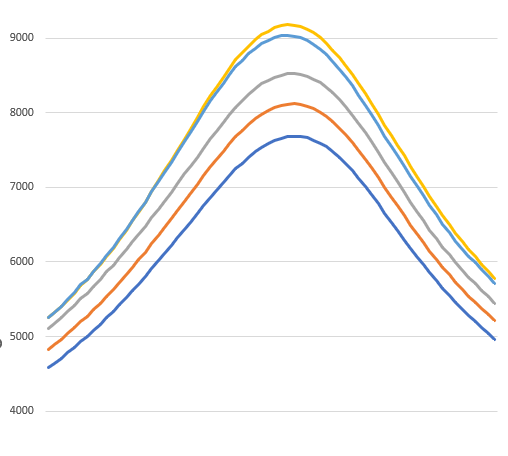
When you’re done, you get a beautiful graph like this:
Data is never that clean! Those are almost perfect Gaussians.
The amplitude of each curve doesn’t matter. That’s just the relative brightness of each LED (and QE of the sensor), with the camera set to manual exposure, so some colors were naturally dimmer than others.
The important part of each curve is the X position of the peak. That’s the ideal focus position. And the thing that jumps out immediately (and also agrees nicely with the pixel size observations) is that the Schneider Componon-S 50mm f/2.8 is achromat corrected.
I’ve never seen this mentioned in any datasheets or in any reviews. The red and blue would be even closer if my red LED was a “standard” red wavelength (620nm) instead deep red at 660nm. If you do the linear regression of each peak (except blue) and project a hypothetical 620nm LED onto the same line, it falls almost exactly on the blue peak.
So, 1/3 of my reason for using a motorized Z-axis has been solved by Schneider. (If only I could get my hands on an apo enlarging lens, I almost wouldn’t need the motor at all… but where would the fun be in that?) 
Planarity
You can use the image’s standard deviation as a focus metric to perform one more cool trick. Instead of calculating it for the whole image, you can slice things into different focus zones:
Then, calculate the standard deviation for just those sub-images and plot them on the same axis.
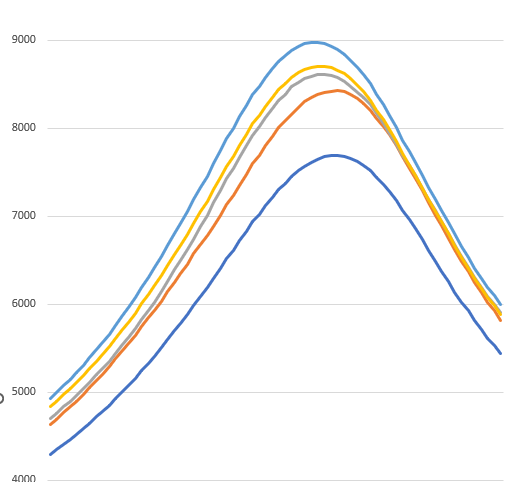
Here are zones A through E for a single color channel, taking an image at each Z-axis motor step:
If the subject plane was aligned perfectly with the sensor plane, all of those curves should have a peak at the same x coordinate, which would mean each part of the image would be entering and leaving focus at the same time. But it wasn’t!
Eventually the film transport is going to be mounted to the same optical tilt/rotation table that I have the calibration slide mounted to now:
Those two knobs can adjust things by a couple degrees on a rotation and tilt plane, which is exactly what we need here. After a couple turns of those micrometer screws, I ran the planarity sweep again and got this back for zones A through E:
That’s a lot closer to being aligned with the camera sensor. I repeated the same for the other direction (zones F through J) and now images are sharper across the whole field of view than before (and the 2D grid pixel measuring algorithm started returning even more consistent results down in the nanometers).
There is an open question about how well the standard deviation metric is going to hold up with Kodachrome as the subject instead of a silvered calibration target, but hopefully I’ll be able to get things dialed in once I switch over to a proper film transport. Planarity seems like something you can dial in once and then forget about unless the machine gets bumped by something.
What’s Next
Focus detection isn’t quite “auto-focus”. Those graphs are still being generated manually in Excel. I want the focus sweep button to find the peaks and set up markers at the best focus positions so I can travel to each in a single button click. That is auto-focus and it’s going to require a little more algorithm design.
That’ll be in June and I’m planning to fill the rest with more integration work as I get closer to actually imaging film: I need to confirm that my software control of the motor (over my new communication protocol) is still as dependable as my early Arduino-only tests re: not missing any steps. I want to get the Arduino connected to the sensor’s GPIO so I can request exact exposure timing instead of just using the default video stream. And it’s probably time to see if I can’t read values from the load cell controller board that will eventually become part of the film transport.