Just normal jpgs (8 bit per channel), transfered from the RP to a client running under Win11. The client stores the files on the hard disk.
Exposure fusion is done later, after the whole scan is done, with a separate program. Another prgram is used for an inital color correction. Yet another program handles temporal denoise. After that, the files are loaded into DaVinci.
Thanks Rolf. I meant the file generated by the exposure fusion (between exposure fusion and initial color correction).
Thinking in terms of best workflow, from the perspective of best dynamic-range = largest bit-depth
My thought was that it would make sense to blend the 8-bit jpegs (or 12 bit raw) into a higher bit-depth intermediary. Something like 16bit TIFF.
That intermediary can be the source for initial color correction, or Resolve (or VirtualDub2), and generate an allow the process to ultimately deliver a video file with higher dynamic range.
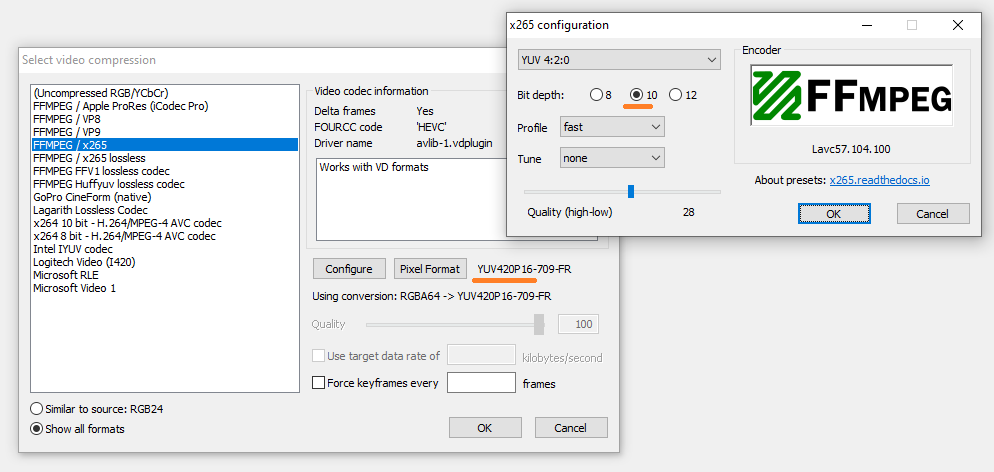
In my first workflow, I started with a single exposure of 12 bit raw (NEF). In Resolve cropped, adjusted levels, and color corrections to a 16bit-TIFF sequence intermediary. Then used NeatVideo with VirtualDub2 to denoise and encode into a 10bit-h265 (my Samsung TV was happy with it).
I have not used Mertens, and probably do not understand it enough, but my thought is:
The fusion bit depth should be of a higher bit-depth than the sources.
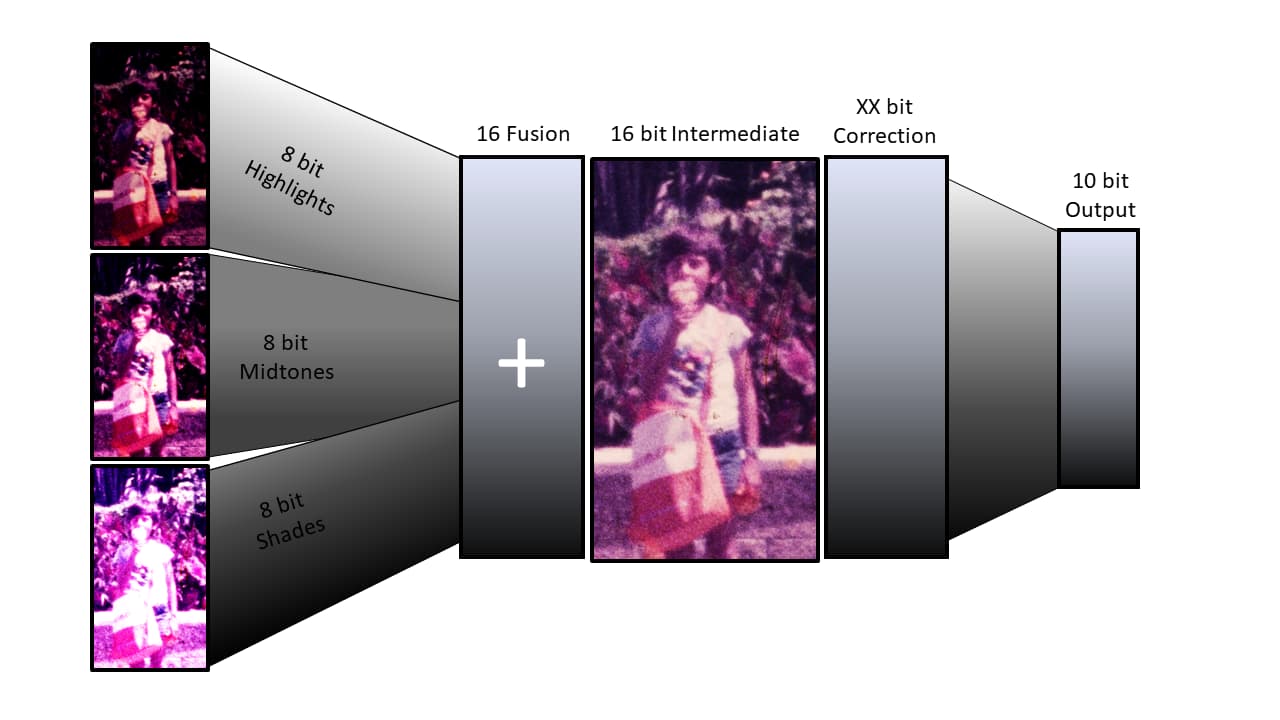
Start with X exposure source files of 8 bit (jpeg) or 12 bit (DNG) (illustrating only 3 for simplicity).
Fuse the exposures into a 16 bit-depth intermediate.
Correct/process with a workflow that keeps higher than 8-bit depth (for example, some plug-ins in VirtualDub2 result in 8bit outputs).
Encode with 10 bit output file for viewing (HDR in the future?)
@PM490 - you’re right on the spot with your scheme.
Here are more details about my current processing pipeline. It is still evolving, by no means finally; one important feature is the progression of bit-depths and image sizes towards the end product. So here we go into the details:
Scan of each single movie frame with 4 exposures (nicknamed ‘Highlight’, ‘Prime’, ‘Shadow1’ and ‘Shadow2’). Sensor resolution (4056,3040)@12bit. Shutter speeds: 2400, 4800, 9600, 19200. Conversion via libcamera and alternative tuning file into (4056,3040)@8bit rec709-encoded .jpgs.
Transfer via LAN-link to PC-client; display and storage of received images.
After full scan of the footage exposure fusion. (4056,3040)-source images are converted to floating-point images and scaled down to (1800,1350) resolution for further processing. This includes sprocket-registration and sub-pixel alignment of each frame stack. Intermediate image is written out at (1800,1350)@16bit. Own software.
An initial color correction on the fused result is done. Either using own software (floating point precision), DaVinci Resolve (presumably also floating-point) or VirtualDub (16 bit processing). Output is written to hard disk (1800,1350)@16 bit.
Restoration step. Basically temporal degraining and sharpening. This is done via an avisynth-script and VirtualDub. Output and processing at (1800,1350)@16bit.
Final edit in DaVinci Resolve. Timeline resolution (1440,1080)@18fps. Color-correction and crop to image frame. Output is whatever is required.
Hope this scheme above is detailed enough.Occasionally, intermediate sizes are chosen somewhat larger than stated ones in order to get some headroom for stabilization of unsteady takes. Also, tests I have done with running the whole pipeline in floating point format did indicate that 16bit intermediates are sufficient for my requirements.
In another twist, I tested scanning up to three differently exposed raw files (.dng) and combining them directly into a raw file with 16bit depth per color channel. I did not notice much difference in the results compared to the above described exposure fusion process.
Note that raw files are linear in image intensities whereas .jpgs have a gamma-curve applied. So the combination of raw files has to be done differently from the exposure fusion done on the .jpg-images. It’s actually much less complicated. Using the standard exposure fusion algorithms for combining data from raw files is probably not going to work.
Continuing the comparison: exposure fused footage has a slight advantage over a 16bit raw. That is because exposure fusion has a build-in optimization step, adjusting image intensities in a way that the output image looks nice. The 16-bit raw obtained by taking several differently exposed raw image and combining them has much more information - but the image is raw. That is, I need to “develop” the image in a second step. That is mostly a manual process. I do this occasionally for important photographs I have taken with my DLSR, but for me, it’s no fun. I certainly do not want to do this for a 20 min Super-8 real with hundreds of differently lit scenes. However,I am still tinkering around with raw-captures.
Last thought: while raw captures at 16 bit are obviously future-proof in terms of switching sometime to a HDR-workflow (when hardware and standards permit it), this is also the case with scanning each film frames as an exposure stack of jpgs. The Debevec algorithm from 1998 covers that nicely - going from a stack of jpgs to a real HDR. I have used this algorithm (in my own implementation) since years, with different cameras/scanners. Very stable algorithm.
What light source are you using? I need like 10x these exposure times for a decent image.
After reading somewhere that HDR should actually be done in RAW, and not in RGB, I was looking into ways to do this. So this sounds very interesting! Would you be willing to share your code?
With the ability of Davinci to use the DNG files directly as a raw 18fps input film, the raw DNG route looks the most interesting to me:
RPI: Capture RAW frames
RPI: Make the DNG files as good as possible (future proof): rec709 / rec2020, color profile, HDR multiple frames?
PC: Pass DNG files directly into Davinci without using other tools to create final output
Having the DNG files directly in Davinci will leave all options open for 4K, HDR, 10bit or whatever would be nice to have in the future (or now even).
I’ve manually created a 1 second (18 frame) clip this way, and it looks so much better than the wolverine version. Can’t wait to receive my stepper motor driver from aliexpress and start actually capturing film.
Well, I think one of the profiles of Jack Hogan is just ASCII-encoded and you might be able to extract the appropriate color matrices and forward matrices, as well as the corresponding calibration illuminants. This might get you going; but maybe the software creating the .dng-files in the first place does use Jack Hogan’s data anyway - as I mentioned, I do not know the current state of affairs here, but there have been developments the last time I checked.
Well, it is a 3d-printed integrated sphere. Used to be equipped with red, green and blue LEDs, nowadays I am using instead three Osram white-light LEDs, specifically Osram Oslon SSL80. The later give a better color definition. Some more information can be found here.
At this point in time, there is not really something I could share. I am still in the process of investigating the best way to do it.
Basically, any raw capture is already a HDR - only, that the range of intensities is limited to the bit range the camera can deliver. This has two consequences. For starters, bright lights might saturate. Of course, you would adjust shutter speed in such a way that this is not the case. However, once you have done this, you will get quantization noise in the low illumination parts of your image. Simply, because the camera is working with evenly spaced intensity levels. You can capture however a second raw with a longer shutter speed, pushing these dark areas into a better range. Of course, in this second capture, all brighter image areas will be blown into the white. Nevertheless, the shadows will be much better defined in your second capture.
For combining these two raws, you need to go from integer numbers to floating point variables. Than you need to multiply the second, brighter exposure with an appropriate scaler which gives you (nearly) identical intensities for image areas present in both images. Once you have this rescaled second exposure available, there are various way (hard/soft threshold for example) to combine both raws into a new image which should have reduced camera and quantization noise in the darker areas of the image.
The information in the darker areas of the image will come from your second, brighter exposure, the information in the brighter image areas from your initial base exposure. That’s it, basically. The challenges in this approach are hidden in the way the two exposures are combined; this will have an effect on how much the end result will be affected by image and quantization noise. I am still doing some research here.
Technically, a true HDR records just the radiance of the scene. So there will never be any rec709 or any other profile hidden in an HDR. Same is true for raw images: a gamma-/contrast-curve is not applicable for raw data (usually - newer sensors kind of deviate). Raw values are linear values (again: mostly).
Let’s get a little bit more into the details:
Raspberry Pi software captures (or at least did capture) raw sensor data into various non-standard formats onto the hard disk. Some of these raw file formats were proprietary, some are close to Adobe’s .dng-spec. How close at the moment I do not know.
Raw data is just that: the data the sensor is actually sensing. There is no gamma-curve applied to this data, this is actually one of the last steps done during the development of the raw data. Other steps in the development of the raw include white-balancing and application of the appropriate color matrices. And this is indeed the processing libcamera is applying to the raw data to get from that raw sensor data to the jpg or png which it usually outputs.
Raw data is in a certain sense already a HDR-signal. However, it is quantized to a certain range (10/12/14 bit) and exhibits therefore overflow and quantization noise. That spoils the fun occasionally.
a real HDR is a floating point representation of the radiance of a certain scene. Specifically, its values are unbound. A real HDR is not equivalent to what is called a “HDR” on many internet sites or in any sales material.
exposure fusion via Mertens does not create a real HDR. The goal of exposure fusion is to transform a stack of low dynamical range images (LDR, usually 8 bit) into another image which can be viewed on normal display (that is, actually another LDR image). That is, the output imagecaptures the spirit of all the data contained in the LDR-stack. To achieve this, the dynamic of the original LDR-stack is reduced to something which can be nicely displayed on any standard display (8 bit/channel).
exposure fusion is similar to the normal HDR-process, but does everything in one pass. The normal HDR-process consists of two independent steps: 1) estimating a real HDR from the scene data and 2) tone-map the HDR into a displayable LDR image. Note again the huge difference: this is a two-step procedure, first create a HDR, than tone-mapping it into a displayable LDR. Again, the result of a normal HDR-process is different from the result of exposure fusion.
As noted above, a jpg image output by libcamera has, as one of the final steps, a gamma-curve applied to its values (this gamma-curve could be rec709. In the standard tuning file of the IMX477, the gamma-curve is something someone thought “looks nice”). In any case, the gamma-curve applied as well as other image processing options performed in a camera make the estimation of a HDR image from jpgs non-trivial. Debevec came up with a solution in 1998. He first uses the stack of LDRs to estimate the gain-curve of the camera. Once that gain-curve has been calculated, one has a tool to transform the jpg-image intensities back to their original raw values. Combining these recovered raw values into a single image file gives you finally the HDR you are after.
A true HDR looks rather dull, similar to a non-developed raw. The reason: scene radiances cover normally such a broad range of values that it is impossible to display this on a standard LDR display. Only after a secondary step, the tone-mapping, the HDR content becomes viewable on our average displays. I am not aware of any good tone-mapping algorithm for HDRs. (Just for the record: while a HDR should have the correct colors, the raw file does not. A raw file needs color science to be applied.)
Specifically, developing a raw into something viewable consists of two steps as well: A) get the colors right (that step depends on the camera’s bayer filter) and B) get the intensities right (that usually amounts to remap some intensity ranges which are either too bright or too dark and finally apply an appropriate gamma-curve). The later step is very similar to the tone-mapping of the HDR discussed above.
One idea I have not yet tried in this context is the following: the new libcamera/picamera2 approach does not only give us access to the raw data, but also to the metadata of every single image. Now, we know that the 12bit of the HQ camera is close to sufficient for most color-reversal material, provided that the exposure of each frame is optimized. So, what if we capture the film with autoexposure doing its fine work (optimizing the exposure of the frame to the working range of the sensor) and recording with every frame the values the automatic came up with? Specifically, we should take note of shutter speed, digital and anlag gain of each frame. With this information, one should be able to transform the .dng-files (with varying exposure settings due to the autoexposure working) to a common reference exposure setting which we need for converting the frame sequence into film footage. In the end, such an approach would be something like a poor man’s HDR capture, with limited (12 bit), but adaptable (via the autoexposure algo) dynamical range. Might be something to experiment with, as only a single raw-capture needs to be done for each frame…
Thank you so much @cpixip, the details and insight are much appreciated.
I was thinking of doing some sprocket-registration at the RPi, so I could use it as feedback to minimize the accumulation of errors in the transport. At this time there is no mechanical or optical link to sprocket in the transport controller.
My thought was to detect sprocket at one of the exposures (probably the one with less light), maybe create a sidecard file with the info, feed the detected position error to the transport controller (pico).
I think that VirtualDub2 uses 64 bit processing and depending on the coder converts to 16 or 8 for output.
Thank you for this insight, I missed that fusion required gamma-curve source files. Interesting twist.
In the interest of best dynamic range for all channels, I was thinking that for negative color film it would make sense to figure a way to separate the exposures to capture a better range. In other words, to offset the negative base by exposing certain channels (particularly blue) in a different range.
I don’t have 8mm movie negatives, so would probably only do this as a side project for some 35mm negative stills.
That was my thinking also. Additionally, when used with light intensity control, it allows to use a 12bit sensor to capture an equivalent dynamic range larger than a 16bit sensor.
Thank you for that insight, I have to take a closer look at Mertens vs Debevec.
In working with DaVinci in an underpowered machine, my experience was that the processing time for RAW-source files was significantly more than when using TIFF-source files. In my case I was using NEFF which have compression and uncompressed TIFF, that along may be the tasking factor.
I was actually thinking that an intermediate would be set for best quantization of each channel.
My exploration started with the frustration with scanning reversal Ektachrome film with a fade die (12 bit raw source). When pushing the levers with Resolve the quantization stairs in the Waveform monitor for the fade component are quite visible.
A fusion technique for each color component level would allow using a different exposure range for the components relevant to the fade die.
Y = 0.3 R + 0.59 G + 0.11B. If the exposures are selected for maximum range of Y (specially on a film with fading), It is certain that that the R and B channels would not be using the full 16 bit quantization.
All the above in the context of controlling light for expanding the capture range of each component (white light for me).
Like with RAW, the full-quatization-intermediate (FQI) would require development prior to visualization.
And why would one go through all that trouble?
Capturing of films subject to color fading without pushing the noise at postprocessing.
Better signal to noise per color component.
Better dynamic range per color component.
Future proof the resulting scan for future displays HDR.
Sorry if this is becoming another extended topic (like the illuminant discussion). @PixelPerfect apologies for the pollution to your topic
I’ve used a similar workflow, and the missing link (for me) is to have higher dynamic range. As mentioned above, I have some films with faded dyes.
In my first scanner the camera was a DSLR 12 bit, output 12bit NEFF. The Rpi HQ is also 12bit. Using fusion with a higher bit-depth intermediate to bring into Resolve is an order of magnitude improvement.
If the film is in good shape, and well exposed, a source raw HQ (12bit) will look great, and may be all you need. When things are not ideal (film not exposed correctly / scenes with very high contrast or fade dye) more dynamic range is needed.
@PM490 - may I shamelessly promote this here for that purpose? I am actually using this code in my Raspberry Pi server. The frame for highlights (which is the darkest frame available) is used to detect the position of the sprocket. The usual number of steps my stepper needs to do for one frame advance is 400 steps. Any deviation of the center of the sprocket from the center of the image is simply subtracted from the standard 400 steps before the next move is triggered. The code is fast enough to do this, at least on my RP4, in real-time.
Thank you both for all the in depth information and discussion. There a lot for me to learn and too much for me to respond to right now.
Video editing and color grading is new to me, but here’s the result of using a DNG file directly into DaVinci without using any other software:
I’m happy with the result so far, and I think like this I can do without any extra software between the RPi capture and DaVinci. Making the capture very simple, and hopefully high quality enough.
Fun fact: 1 RAW/DNG file is 17MB and the entire movie clip in “H.264 Master” quality is just 8MB.
This is worth exploring. I am not there yet, but will definitely experiment with if.
Another approach I was considering was, to use autoexposure to determine the exposure settings, and these use these exposure settings as the baseline for selecting the additional exposures for fusion. Say the autoexposure resulted in X, then set exposure to manual and do 1/4 X, 1/2 X, 2 X and 4X. Call it poor-man fusion autoexposure.
Shutter speed and digital gain (ISO) is recorded into the jpeg and dng files. If we set the analog gain to 1.0 we have all the information in the files metadata.
This is almost what the code I posted above does. Here’s an updated version that does exactly that:
Use new integrated tuning file “imx477_scientific.json” (thanks @cpixip !)
Maximize the intensities to 0.0 … 1.0 after merge as suggested by @cpixip , this improved the resulting image quite a bit! However, can we safely do this when we are using linear intesities?
Don’t capture the autoexposure image twice
Use easy to change exposure settings: exposures = [-2, -1, +1, +2]
The resulting image now looks better, so I’m starting to see a point in using mertens merge .
Perhaps I’ll put the code in github or gitlab later. It would be nice if we can have all knowledge for creating the best image quality combined into 1 simple example code somewhere.
@cpixip First of all, thanks for sharing your experience on the forum.
I am going to try to reproduce, at least partially, your working method in my software.
At the moment I have installed the Bullseye version of the operating system on my RPi3.
To my surprise, I discovered that the old Picamera library was installed by default when, according to my idea, this old library and the old camera interface were not compatible with Bullseye.
In the raspi-config utility, main menu option 3 (Interface Options), there is an option to activate the camera with the old interface (option I1 Legacy Camera).
What has been most curious to me is that this compatibility was added to Bullseye as of December 2021, and yet I have not seen any comments about it.
@Manuel_Angel: Well, Manuel, as you might recall from some of my posts here on the forum, I was not too happy with the new libcamera/picamera2 move by the Raspberry Pi foundation. I still find libcamera a horrible peace of software, but, alas, it’s the future…
One thing which is actually good within the libcamera-context is the tuning file - this allows you to specify in detail how the images look which are delivered by libcamera. Unfortunately, nothing is documented here - so it took me quite some time to understand what goes wrong in the standard tuning file and how it could be improved. The new imx477_scientific.json tuning file is a first attempt on this, but I consider it not (yet) the final answer. Another aspect is the evolution of the picamera2-lib, which covers up some other issues of libcamera. So at this point in time, I think the libcamera/picamera2 combo starts to outperform the old way of doing things. However, older software needs to be redesigned, and there is more effort required than simply renaming a few subroutine calls. That is probably the reason the foundation re-enabled the legacy stuff.
I have converted my capture software to the new library, as it is given me more control on what the camera delivers. There are still challenges; for example, the user has no access to the digital gain control, as this is used to simulate the shutter speed a user requested. A shutter speed of 9600 might either be realized by a real shutter speed of 9600 and a digital gain of 1.0, or by a shutter speed of, say, 4600 with a digital gain of 2.0. Of course, both captures are only approximately equivalent. This introduces the necessity of additional code checking both shutter speed and digital gain in the returned metadata. Oh well, that’s life
The line 266600 1.0 1.0001050233840942 False 0 True consists of:
shutter speed
analog gain
digital gain
AeEnabled
Number of captures since AeEnabled
AeLocked
In my code I’m waiting for AeEnabled, AeLocked, analog gain == 1.0, digital gain < 1.01. In total this takes 23 captures (@ 10fps) to complete:
the 6th capture seems to have analog gain == 1.0
the 11th capture has “AeLocked”, however, the digital gain seems not ‘locked’ but still settling slowly towards 1.0.
the 23rd capture meets my requirements of the digital gain being less than 1.01.
That is an unacceptable amount of time (23 captures @10fps == 2.3 seconds). Anyone having the same issue or knows a workaround? The digital gain never seems to settle to true “1.0”, where I would like it to be. Is this caused by the requested shutter time? Is there a known formula for shutter time values that result in a digital gain of exactly 1.0?
But besides this finding, I have been thinking is I should be doing automatic exposure at all? When using a projector, the light bulb also does not change intensity depending on the exposure of the frame. A dark frame is just… dark.
So would it not make sense to calibrate the shutter time only once, so that the light source pure white is captured as 254, 254, 254 ? Then use this fixed shutter speed (with or without HDR) to capture the entire film? That way dark frames in the film will be dark in the capture, and bright frames in the film will be no brighter than 254, 254, 254.
If the dynamic range of the capture is good enough for the dark parts in bright frames, then it should also be good enough for dark frames, right? And vice versa, if dark frames need longer shutter speeds to capture all detail, then the same goes for dark parts in bright frames.
So back to HDR using picamera2. I think without switching from automatic to manual exposure it would be possible to get a decent speed. Currently the fixed shutter speeds of EV-1, +1 and +2 take 6+5+4 frames = 12 frames. I’m now experimenting with trying to reduce the number of frames needed for the shutter time to “settle”. I can’t even call it “settle”, becouse it just seems to jump from the old shutter speed to the new shutter speed in 1 frame. So perhaps if I can queue the right shutter speeds, it will also output the right shutter speeds, delayed by a few frames.
I am not sufficiently familiar with the shutter/gain behavior, you are a bit ahead of me, I am already working with the camera but haven’t had the time. However, the line above, where the shutter seems to jump made me think of a light source that is not constant current. Is your light source controlled in any way by PWM or AC? that may be part of the issue.
I’m using 5v DC power with a 50Ohm resistor to drive the LED from the Wolverine. I do not know what type of LED is inside and if I can increase the voltage (or decrease the resistor) to get more brightness. But I will investigate this later.
With “jumping” I just mean it jumps to the requested shutter speed, there is no settling time or anything. There is just a delay. For instance in the above example:
set to 133314us
capture 1 = 33314us ← old shutter speed
capture 2 = 33314us ← old shutter speed
capture 3 = 33314us ← old shutter speed
capture 4 = 33314us ← old shutter speed
capture 5 = 133285us ← “jump” to requested shutter speed
The strange thing is, I set the queue depth to 2. So I was expecting the shutter time setting to be visible after a delay of 2 captures.
I have by now managed to capture HDR much faster using picamera2, and will share the code soon.
At shorter shutter times the digital gain will go to 1.0. I do not know why at larger shutter times it seems impossible to get a digital gain of 1.0. Even if I set the shutter speed to a value I know the sensor can handle (for instance becouse the last capture DID use that shutter speed), then the resulting shutter speed will be a little less, and the digital gain will again be a little more than 1.0.
I think this issue will be worked around for me once I increase the LED brightness.
… this is one of the little things which make it more complicated to use the new libcamera/picamera2
As noted in my post above, libcamera does a trick to deliver an approximation to a certain shutter speed the user has requested. The basic reason for this is that any sensor available can only realize a set certain shutter speeds in hardware - other shutter speeds can not be realized. The old way of handling that was simply to work with a shutter speed closest to the one the user had requested. The new way: change the digital gain in such a way that the product with the hardware realizable shutter speed gives you the requested one. That’s the reason why in the libcamera-context digital gain is no longer available as a user parameter.
There is one way to handle this issue: only request shutter speeds which are realizable by the hardware anyway. You can find out these values by monitoring (as you did above) the value of the digital gain the HQ camera comes up with. If it is close to one, you have found such a hardware shutter speed. Ideally, the value of the digital gain should be exactly 1.0. I am using shutter speeds with digitalGain < 1.001 for my purposes.
Of course, this is only half of the story. In the background of libcamera, there is an algorithm working which tunes the digital gain. And this algorithm needs some frames to converge to a decent value. That is what you are seeing in the above printout. As I said above: you might be asking for a shutter speed of 9600 with a digitalGain of 1.0, but libcamera might deliver you instead a shutter speed of 4800 with a digitalGain of 2.0.
The way to handle this is to always check the metadata returned with the frame for the correct value of digitalGain. (It was actually worse a few months ago, but the Raspberry Pi guys did some work to improve the situation.)
Another issue within the libcamera-context is that any change of shutter speed (or any other parameter for that matter) needs to travel through the pipeline back to the sensor until that change is actually applied. That is, if I request at frame 1 a different exposure, it will take between 12 to 15 frames for that exposure value to show up in the delivered frame. This is not an issue with the code you are currently using, as here the camera is always started and stopped between different exposures. But for faster scanning, you will probably opt to keep the camera running and just changes things on the fly. In this mode of operation, you will notice that the image you want will be delivered only after a delay of 1-2 sec (when running in the highest resolution mode).
There is a way to circumvent this, and the basic idea comes from David Plowman, the maintainer of the picamera2-lib: circle constantly through all the exposures you are interested in and check the metadata returned with each frame for the combination you are interested in. Once received, delete this exposure from your list and continue to circle through the remaining exposures continuously. Repeat until the list is empty, than move on to the next frame.
There is yet another twist here, which is due to the digital gain issue: the camera tends to cheat on you, delivering a requested shutter speed of 9600 sometimes by approximating this with a shutter speed of 4800, but a digitalGain of 2.0. So you need to give the camera some time to converge. That is, instead of constantly cycling through your list of exposure values, you need to request a certain exposure value for several frames. From my experience, three requests in a row are sort of optimal for the current libcamera.
Actually, if you capture anyway a stack of differently exposed images (LDR-stack), it is probably better to work with fixed exposures. Any automatic exposure will fail under certain circumstances.
You should tune your darkest exposure in such a way that the maximal intensity of your frame (without film) is for sure lower than 250 (jpg) or 4096 (raw). I usually adjust that value to something around 240 for jpgs, just to have some headroom.
#!/usr/bin/python3
import cv2
import numpy as np
from picamera2 import Picamera2, Preview
from libcamera import Transform
# Print metadata
def metaprint(m):
#print(m)
print(m["ExposureTime"], m["AnalogueGain"], m["DigitalGain"])
# Drop [count] number of captures from camera
def drop(count):
for c in range(count):
request = picam2.capture_request()
metaprint(request.get_metadata())
request.release()
# Capture a specific exposure time from camera
def capture(images, exposure):
for c in range(10):
request = picam2.capture_request()
metadata = request.get_metadata()
metaprint(metadata)
if metadata["ExposureTime"] == int(baseExposure*2**exposure):
if metadata["AnalogueGain"] != 1.0:
print(f'Warning: AnalogueGain = {metadata["AnalogueGain"]}')
if metadata["DigitalGain"] != 1.0:
print(f'Warning: DigitalGain = {metadata["DigitalGain"]}')
images.append(request.make_array("main"))
request.release()
return
request.release()
print(f'Error: EV{exposure:+} not found!')
# Capture 4 exposures, and merge them using mertens
def capture_mertens(path):
print(f'Capturing HDR image @{path}')
# Set exposure to EV-1, and drop 1st capture from camera queue
picam2.controls.ExposureTime = int(baseExposure*2**-1)
drop(1)
# Set exposure to EV-0, and drop 2nd capture from camera queue
picam2.controls.ExposureTime = int(baseExposure*2**0)
drop(1)
# Set exposure to EV+1, and drop 3rd capture from camera queue
picam2.controls.ExposureTime = int(baseExposure*2**1)
drop(1)
# Set exposure to EV+2
picam2.controls.ExposureTime = int(baseExposure*2**2)
# Capture frames 5,6,7,8
images = []
capture(images, -1)
capture(images, 0)
capture(images, 1)
capture(images, 2)
# Return exposure to EV-1
picam2.controls.ExposureTime = int(baseExposure*2**-1)
# Align images
#alignMTB = cv2.createAlignMTB()
#alignMTB.process(images, images)
# Mertens merge all images
print(f'- mertens merge')
merge = cv2.createMergeMertens()
merged = merge.process(images)
# Normalize the image to 0.0 .. 1.0
merged = cv2.normalize(merged, None, 0., 1., cv2.NORM_MINMAX)
# Convert to 8bit
merged = np.clip(merged * 255, 0, 255).astype(np.uint8)
cv2.imwrite(f'{path}_result.jpg', merged)
print(f'- done')
# Initialize camera, tuning and configuration
tuning = Picamera2.load_tuning_file("imx477_scientific.json")
picam2 = Picamera2(tuning=tuning)
capture_config = picam2.create_still_configuration(lores={}, main={"size": (2028, 1520), "format": "RGB888"}, raw={"size": picam2.sensor_resolution}, transform=Transform(hflip=1), buffer_count=2, display="lores")
picam2.configure(capture_config)
picam2.controls.AeEnable = False
picam2.controls.AnalogueGain = 1.0
picam2.controls.ColourGains = (4.35, 1.05) # calibrated red/blue gain (white balance)
picam2.controls.FrameDurationLimits = (10, 100000)
baseExposure = 24000 # calibrated base exposure time
# Start the camera with preview window
#picam2.start_preview(Preview.QTGL)
picam2.start()
# Give the camera some time to settle (drop 10 captures)
picam2.controls.ExposureTime = int(baseExposure*2**-1)
drop(10)
# Your code here; capture the film
for frame in range(10):
capture_mertens(f'output/film01_frame{frame}')
# Stop the camera
picam2.stop()
As you can see I waste 6 captures, and use 4 captures. In total 10 captures = 1 second needed per HDR scan.
Ah nice one! I’ll try to improve the code further. If the looping over the 4 exposures is done in a separate thread, then we can perhaps use ALL captures from the camera.
You might want to have a look at the code posted here.
Great! And in effect, I am mildly surprised. Normally, the switching from one exposure to another one takes between 1-3 frames, with intermediate frames approximating the requested exposure via a digital gain not equal 1.0. Maybe the Raspberry Pi guys improved things? I would have expected some error messages in your log, like “Warning: DigitalGain = …” when switching shutter speed.
One second per HDR-scan is fast.Did you try to lower the number of frames you idle away at the beginning of each sequence? If you transfer the LDR-stack to a PC and save the stack there for an offline exposure fusion, you might end up with a system scan time of about 2 sec, including about a 1 sec allocated for film transport.
I got HDR working at the theoretical maximum speed: 4 frames, in 0.4 seconds, continuously. And they all have AnalogGain=1.0 and DigitalGain=1.0
I put the code into a class for easy usage, and I’m hoping there’s python guru’s here that can improve on the python code (I’m used to assembly/c/c++ coding, python is new to me). Here it is:
Basically the thread is continously changing the exposure time, and clearing out the camera queue. As soon as the capture thread wants to capture 4 images we start saving the images into an array.
The using code looks like this (simplified):
from hdr_capture import HDRCapture
hdr = HDRCapture()
hdr.start()
while True:
images = hdr.get_images()
process(images)
move_next_frame()
hdr.stop()
hdr.join()
Note that I’m using create_still_configuration with buffer_count=2 to reduce the number of frames the camera queues. Perhaps this is causing the difference?
Guess I lowered it to 0 now . I received my stepper motor driver today and already got something working. Capturing and saving 4 exposures + moving to the next frame takes a total of 1.5 seconds. Note that I start moving to the next frame, and start saving the jpegs, at exactly the same time to save some time. I guess showing the full code makes it clear better than I can explain, so here’s the full code as well (sorry for spamming with code):
#!/usr/bin/python3
import sys
import cv2
import time
import numpy as np
from hdr_capture import HDRCapture
from HR8825 import HR8825
from threading import Thread
# Wolverine stepper motor
Motor1 = HR8825(dir_pin=13, step_pin=19, enable_pin=12, mode_pins=(16, 17, 20))
Motor1.SetMicroStep('hardward' ,'1/32step')
# Start the HDR capture thread
hdr = HDRCapture()
hdr.start()
def next_frame():
# Move to next frame
Motor1.TurnStep(Dir='forward', steps=50 * 32, stepdelay=0.000005)
Motor1.Stop()
# Motion settle time + camera queue process time
time.sleep(0.4)
# Your code here; capture the film
for frame in range(int(sys.argv[1])):
print(time.time())
# Get multi exposured images
images = hdr.get_images()
x = Thread(target=next_frame)
x.start()
mm = False
if mm == False:
# Save individually exposed images
print(f'- Saving separate jpeg images...')
cv2.imwrite(f'output/film01_frame{frame}(0)EV-1.jpg', images[0])
cv2.imwrite(f'output/film01_frame{frame}(1)EV-0.jpg', images[1])
cv2.imwrite(f'output/film01_frame{frame}(2)EV+1.jpg', images[2])
cv2.imwrite(f'output/film01_frame{frame}(3)EV+2.jpg', images[3])
else:
# Mertens merge images
print(f'- mertens merge...')
merge = cv2.createMergeMertens()
merged = merge.process(images)
# Normalize the image to 0.0 .. 1.0
merged = cv2.normalize(merged, None, 0., 1., cv2.NORM_MINMAX)
# Convert to 8bit
merged = np.clip(merged * 255, 0, 255).astype(np.uint8)
# Write to file
cv2.imwrite(f'output/film01_frame{frame}.jpg', merged)
x.join()
print(f'- done')
hdr.stop()
hdr.join()
On to the more difficult problems:
The Wolverine LED is not bright enough, and I can’t find out what exact LED it is. I’ve already lowered the 50Ohm resistance to 33Ohm, but it’s still not enough to stay under 100ms exposure time for the EV-1 exposure (I need 240ms now). I’m afraid I’ll burn the LED if I put more current through it.
The film gets out of focus on some frames, because it’s not held firmly flat in the gate, causing the film to sometimes be 1mm higher or lower, causing it to be out of focus.