Mentioned that above (see: " Comparison Scan 2020 vs Scan 2024"-thread), in addition, search the forum for the “degrain” keyword.
The first discussion about the noticable noise floor especially of the red channel was actually already here.
However, up to my knowledge, no one did so far some experiments into that specific topic.
My suspicion is that it is caused by the rather large gain multiplier of the red and blue color channels, compared to the green channel. My current operating point is redGain = 2.89 and blueGain = 2.1 - this gives me the correct color balance (whitepoint) on my scanner. Your own gain values, redGain = 2.8 and blueGain = 1.9 are not too far off from this.
The gain values necessary to map “white” of your footage to “white” on your raw capture depend on the characteristics of the light source you are using. In case you are using a whitelight LED illumination, you have no chance of fiddling around with that. Except you capture three consecutive raws, each optimized for each color channel, red, green and blue. That will triple your capture time. In addition, you end up with a scan where the color science needs more work during postprocessing, as “white” is not “white”, initially.
The other approach with respect to illumination (and I used to work with that) is what @PM490 is doing: using individual color LEDs for the red, green and blue channels. With such a setup, you can adjust each color channel optimally in terms of the dynamic range. However, proper color science becomes even more challenging as you sample the full spectrum of your source media only at very narrow bands. If you are unlucky, the sampling positions of your red, green and blue LED do not match well with the color response curves of your media, leading to color shifts - how strong that effect might be is currently unknown to me. There are professional scanners out there which use this approach and it is even recommended by some papers for severly faded material - I for my part switched from single LEDs to whitelight LEDs some time ago because I did not want to put too much work in postprocessing.
Let’s approach this from another perspective. The dynamic range of color-reversal film certainly exceeds the maximal dynamic range the HQ sensor can deliver. The HQ sensor works with 12 bit raw capture (if you select the correct mode), and old film stock can require up to 14-15 bits of dynamic range, depending on the type of film stock and the scene recorded. On average however, you normally encounter scenes requiring dynamic ranges in the order of 11 bit at most - so on the average, one should be fine with the HQ sensor.
Given, the rather large gain multipliers for the red and blue channel introduce additional noise in the capture. But this noise is present only in rather dark image areas. And most of the time, you would not want to push these image areas way out of the shadows. So these image areas will end up rather dark anyway in your final grade, resulting in noise which is not too annoying.
There are two postprocessing approaches here worth to be discussed. One is the “the grain is the picture” approach, striving to capture the dancing film grain as good as possible. The other one is the “content is the picture” where you would employ temporal degraining techniques to reduce film grain and recover image detail which is otherwise invisible in the footage.
Now, in case you are in the “grain is the picture” fraction: note that especially in S8 footage the film grain will be much larger (noisier) in dark shadow areas than areas which are feature a medium or even rather bright exposure. In the end, the film grain in the shadow areas will cover up the sensor noise in the red and blue channels by a large margin.
Well, in case you are employing any grain reduction process (“get rid of the grain, recover hidden image information”): this will of course also treat the sensor’s noise as well. So not only the film grain is gone, but also the sensor noise in the image.
So… - do we really need to care about the noise? Most probably not for most use cases.
I can only see a few scenarious were one would want to optimize the signal path to obtain better results:
- Recovering severly underexposed footage. One example I have is a pan from the
Griffith observatory in LA in the middle of the night - it’s basically black, with a few city lights shining through the blackness. The nice pattern of streets with cars I thought I was recording is not visible at all. But frankly, in a 2024 version of that film, I would simply throw out that scene… - Working with severly faded film. Well, I do not have such footage. But here, you have no chance at all to even come close to a sensible color science. So in this case, I would certainly opt for a LED illumination with carefully chosen narrowband LEDs, each adjustable independently for the film stock at hand. So a single capture should do. Simply for time reasons, I would not opt for averaging several raws or for capturing three independent exposures, each optimized for a single color channel. For me, that would only be an option if I did not have an adjustable illumination.
Finishing this post, I want again promote that you chose your exposure time wisely. Note that with the HQ sensor (and libcamera/picamera2), you are not limited by the usual exposure times your DSLR is using. My standard exposure time is for example 3594 us, which translates into `1/278’. Also, do not use the sprocket area for setting the exposure. Even in burned-out areas of the footage, the “clear” film base eats away some light. Here’s a quick visualization from RawTherapee:
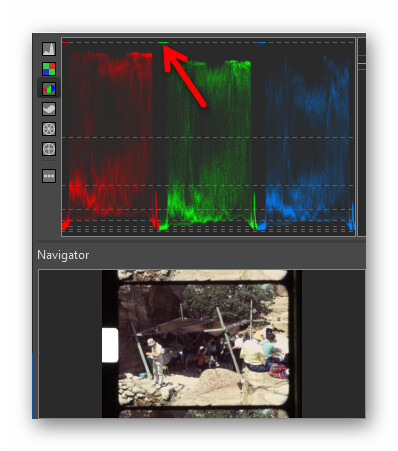
I marked the intensities of the sprocket hole in the green channel with an arrow. As one can see, the sprocket hole is at 100% intensity. But: even the brightest image areas are way below the 100% line. In other words, I could have increased the exposure time in this capture even further without compromising the highlight areas.